博客
- 版本发布
- OpenFunction v1.2.0 发布:集成 KEDA http-addon 作为同步函数运行时
- OpenFunction v1.1.0 发布:支持 Dapr 状态管理,重构函数触发器
- OpenFunction v1.0.0 发布:集成 WasmEdge,支持 Wasm 函数和更完整的 CI/CD
- OpenFunction v0.8.0 发布:通过 Dapr Proxy 加速函数启动
- OpenFunction 0.7.0 发布: OpenFunction Gateway、多语言及 Helm 安装支持
- OpenFunction 0.6.0 发布: FaaS 可观测性、HTTP 同步函数能力增强及更多特性
- Release v0.4.0
- Release v0.3.1
- Release v0.3.0
- Release v0.2.0
- Release v0.1.0
- 技术博客
版本发布
OpenFunction v1.2.0 发布:集成 KEDA http-addon 作为同步函数运行时
OpenFunction 是一个开源的云原生 FaaS(Function as a Service,函数即服务)平台,旨在帮助开发者专注于业务逻辑的研发。我们非常高兴地宣布 OpenFunction 又迎来了一次重要的更新,即 v1.2.0 版本的发布!
本次更新中,我们继续致力于为开发者们提供更加灵活和强大的工具,并在此基础上加入了一些新的功能点。该版本集成了 KEDA http-addon 作为同步函数运行时;支持在启用 SkyWalking 跟踪时添加环境变量;支持记录构建时间等。此外,还升级了部分组件及修复了多项 bug。
以下是该版本更新的主要内容:
集成 KEDA http-addon 作为同步函数运行时
KEDA http-addon 是一个 KEDA 的附加组件,它可以根据 HTTP 流量的变化自动地调整 HTTP 服务器的规模(包括从零开始扩容和缩容到零)。
KEDA http-addon 的工作原理是,它会在 Kubernetes 集群中创建一个名为 Interceptor 的组件,用来接收所有的 HTTP 请求,并将请求转发给目标应用。同时,它会将请求队列的长度报告给一个名为 External Scaler 的组件,用来触发 KEDA 的自动扩缩容机制。这样,你的 HTTP 应用就可以根据实际的流量需求动态地调整副本数。
在 OpenFunction v1.2.0 版本中,我们集成了 KEDA http-addon 作为同步函数运行时的一种选择。这意味着,你可以使用 OpenFunction 来创建和管理基于 HTTP 的函数,并利用 KEDA http-addon 的能力来实现高效且灵活的弹性伸缩。你只需在创建 Function 资源时指定 serving.triggers[*].http.engine 的值为 keda ,并且在 serving.scaleOptions 中配置 keda.httpScaledObject 相关参数,就可以部署和运行你的 HTTP 函数了。
支持在启用 SkyWalking 跟踪时添加环境变量
SkyWalking 是一个开源的应用性能监控(APM)系统,它可以帮助你观察和分析你的应用在不同环境中的运行状况。OpenFunction 支持在部署函数时启用 SkyWalking 跟踪,以便你可以更好地理解和优化你的函数性能。
在 OpenFunction v1.2.0 版本中,我们增加了一个新的功能,即支持在启用 SkyWalking 跟踪时添加环境变量。这样,你可以在创建 Function 资源时指定一些自定义的环境变量来控制 SkyWalking 的一些配置参数。这些环境变量会被传递给函数容器,并影响 SkyWalking 的采集和上报行为。
当 Function、Builder 和 Serving 状态变化时支持记录事件
事件(Event)是 Kubernetes 中一种重要的资源类型,它可以记录集群中发生的一些重要或者有趣的事情。事件可以帮助用户和开发者了解集群中资源的状态变化和异常情况,并采取相应的措施。
在 OpenFunction v1.2.0 版本中,我们支持当 Function、Builder 和 Serving 状态变化时记录事件。这样,你可以通过查看事件来获取更多关于函数构建和运行过程中发生的事情的信息。例如,你可以看到函数构建开始、结束、失败等事件;函数运行时创建、更新、删除等事件。
其他的改进和优化
除了上述的主要变化,该版本还有以下更改和增强:
- 升级了 KEDA 到 v2.10.1 ,HPA(自动伸缩)API 版本到 v2 ,提高了稳定性和兼容性
- 支持记录构建时间,以便你可以了解函数构建的耗时情况
- 调整了 CI 流程,修复了一些小问题
- 修复了一个在 keda http-addon 运行时中的 bug ,该 bug 会导致函数无法正常运行
- 升级了 charts 中的一些组件,包括 keda ,dapr 和 contour ,以保持最新的版本和功能
以上就是 OpenFunction v1.2.0 的主要功能变化,在此十分感谢各位贡献者的参与和贡献。
了解更多关于 OpenFunction 和本次版本更新的信息,欢迎访问我们的官方网站和 Github 页面。
OpenFunction v1.1.0 发布:支持 Dapr 状态管理,重构函数触发器
OpenFunction 是一个开源的云原生 FaaS(Function as a Service,函数即服务)平台,旨在帮助开发者专注于业务逻辑的研发。在过去的几个月里,OpenFunction 社区一直在努力工作,为 OpenFunction 1.1.0 版本的发布做准备。今天,我们非常高兴地宣布 OpenFunction 1.1.0 已经发布了!感谢社区各位小伙伴的贡献和反馈!
OpenFunction 1.1.0 版本带来了两个新的功能:新增 v1beta2 API,支持 Dapr 状态管理。此外,该版本还有多项强化(重构函数触发器等)及 bug 修复,使 OpenFunction 更加稳定和易用。
以下是本次版本更新的主要内容:
新增 v1beta2 API
在此版本中,我们新增了 v1beta2 API,原 v1beta1 API 已弃用,将来会被删除。v1beta2 中有不少重构,你可以在这个 proposal 中了解更多细节。
支持 Dapr 状态管理
之前,OpenFunction 支持 Dapr 发布/订阅和绑定构建块,状态管理也是有用的构建块之一,它对于具有状态的函数非常有用。使用状态存储组件,您可以构建具有持久状态的函数,这些函数可以保存和恢复它们的状态。
现在你可以在 Function CR 中定义状态存储,OpenFunction 将管理相应的 Dapr 组件。
你的函数可以使用简单封装的 Dapr 的状态管理 API 来保存、读取和查询定义的状态存储中的键/值对。
重构函数触发器
之前,我们使用 runtime: knative 和 runtime: async 来区分同步和异步函数,这会增加学习曲线。实际上,同步和异步函数之间的区别在于触发类型:
- 同步函数由 HTTP 事件触发,这可以通过指定
runtime: knative来定义。 - 异步函数由 Dapr 绑定组件或 Dapr 发布者事件触发。要指定异步函数的触发器,必须同时使用
runtime: async和inputs。
因此,我们可以使用 triggers 来替代 runtime 和 inputs。
HTTP Trigger 通过 HTTP 请求触发一个函数。您可以这样定义一个 HTTP Trigger:
apiVersion: core.openfunction.io/v1beta2
kind: Function
metadata:
name: function-sample
spec:
serving:
triggers:
http:
port: 8080
route:
rules:
- matches:
- path:
type: PathPrefix
value: /echo
Dapr Trigger 使用 Dapr bindings 或 Dapr pubsub 的事件触发一个函数。你可以用 Dapr Trigger 定义一个函数:
apiVersion: core.openfunction.io/v1beta2
kind: Function
metadata:
name: logs-async-handler
namespace: default
spec:
serving:
bindings:
kafka-receiver:
metadata:
- name: brokers
value: kafka-server-kafka-brokers:9092
- name: authRequired
value: "false"
- name: publishTopic
value: logs
- name: topics
value: logs
- name: consumerGroup
value: logs-handler
type: bindings.kafka
version: v1
triggers:
dapr:
- name: kafka-receiver
type: bindings.kafka
其他改进和优化
- 从网关状态中删除 lastTransitionTime 字段,以防止频繁触发 reconcile。
- 允许在创建 Dapr 组件时设置作用域。
- 使用 OpenFunction 策略时,支持设置缓存镜像以提高构建性能。
- 支持设置 OpenFunction 构建策略的 bash 镜像。
以上就是 OpenFunction v1.1.0 的主要功能变化,在此十分感谢各位贡献者的参与和贡献。如果您正在寻找一款高效、灵活的云原生函数开发平台,那么 OpenFunction v1.1.0 绝对不容错过。
了解更多关于 OpenFunction 和本次版本更新的信息,欢迎访问我们的官方网站和 Github 页面。
OpenFunction v1.0.0 发布:集成 WasmEdge,支持 Wasm 函数和更完整的 CI/CD
OpenFunction 是一个开源的云原生 FaaS(Function as a Service,函数即服务)平台,旨在帮助开发者专注于业务逻辑的研发。今天,我们非常高兴地宣布 OpenFunction 迎来了一次重要的更新,即 v1.0.0 版本的发布!
本次更新中,我们继续致力于为开发者们提供更加灵活和强大的工具,并在此基础上加入了一些新的功能点。其中,该版本集成了 WasmEdge 以支持 Wasm 函数;我们还对 OpenFunction 的 CI/CD 功能进行了增强,提供了相对完整的端到端的 CI/CD 功能;除此之外,我们还在这个版本中新增了从本地代码直接构建函数或应用的镜像的功能,让开发者可以更加便捷地进行代码发布和部署。
与此同时,我们也在大力优化 OpenFunction 的性能和代码质量,使其更加稳定高效。
以下是本次版本更新的主要内容:
集成 WasmEdge,支持 Wasm 函数
WasmEdge 是一个轻量级、高性能和可扩展的 WebAssembly 运行时,适用于云原生、边缘和去中心化应用程序。它为 Serverless 应用程序、嵌入式功能、微服务、智能合约和物联网设备提供支持。
OpenFunction 现在支持构建和运行以 WasmEdge 为运行时的 Wasm 函数或应用。WasmEdge 成为 Docker、Containerd 和 CRI-O 之外的容器运行时的新选择。
Wasm 函数示例
cat <<EOF | kubectl apply -f -
apiVersion: core.openfunction.io/v1beta1
kind: Function
metadata:
name: wasmedge-http-server
spec:
workloadRuntime: wasmedge
image: openfunctiondev/wasmedge_http_server:0.1.0
imageCredentials:
name: push-secret
build:
dockerfile: Dockerfile
srcRepo:
revision: main
sourceSubPath: functions/knative/wasmedge/http-server
url: https://github.com/OpenFunction/samples
port: 8080
route:
rules:
- matches:
- path:
type: PathPrefix
value: /echo
serving:
runtime: knative
scaleOptions:
minReplicas: 0
template:
containers:
- command:
- /wasmedge_hyper_server.wasm
imagePullPolicy: IfNotPresent
livenessProbe:
initialDelaySeconds: 3
periodSeconds: 30
tcpSocket:
port: 8080
name: function
EOF
借助 WasmEdge 引擎,开发者可以使用多种支持 Wasm 的语言和开发框架来编写及运行函数。
如何构建和运行 Wasm functions,请参考官方文档 Wasm Functions。
更完整的 CI/CD
之前,用户可以使用 OpenFunction 将函数或应用程序源代码构建为容器镜像,然后直接将构建的镜像部署到底层的同步或异步 Serverless 运行时,而无需用户干预。
但是,OpenFunction 不能在函数或应用程序源代码发生更改时重新构建镜像并重新部署它,也不能在镜像更改时重新部署它(例如手动构建和推送镜像或在其他函数中构建镜像)。
从 v1.0.0 开始,OpenFunction 在新的组件 Revision Controller 中增加了检测源代码或镜像变更的能力,并且可以在检测到变更后触发镜像重新构建或重新部署新的镜像。Revision Controller 的能力包括:
- 检测 GitHub、GitLab 或 Gitee 中的源代码变更,然后在源代码变更时重新构建并重新部署新的镜像。
- 检测包含源代码的镜像(Bundle Container Image)的变更,然后在该镜像变更时重新构建和重新部署新的镜像。
- 检测函数或应用程序镜像变更,然后在函数或应用程序镜像变更时重新部署新的镜像。
更好的 CI/CD 功能确保了代码能在不同的环境中高效运行,使用者可以在开发和部署过程中更好的控制版本和代码质量,同时也为使用者提供了更好的使用体验。
此处请参考官方文档 CI/CD。
从本地源代码构建函数
目前,OpenFunction v1.0.0 支持根据本地的源代码构建函数或应用。只需要将本地源代码打包到容器镜像中,并将此镜像推送到容器镜像仓库即可完成构建。以下为操作方法。
假设你的源代码在 samples 目录中,你可以根据以下 Dockerfile 来构建包含源代码的镜像。
FROM scratch
WORKDIR /
COPY samples samples/
然后如下操作:
docker build -t <your registry name>/sample-source-code:latest -f </path/to/the/dockerfile> .
docker push <your registry name>/sample-source-code:latest
推荐使用空镜像
scratch作为基础镜像构建包含源代码的镜像,非空基础镜像可能会导致源代码拷贝失败。
另外还需要定义字段 spec.build.srcRepo.bundleContainer.image。
apiVersion: core.openfunction.io/v1beta1
kind: Function
metadata:
name: logs-async-handler
spec:
build:
srcRepo:
bundleContainer:
image: openfunctiondev/sample-source-code:latest
sourceSubPath: "/samples/functions/async/logs-handler-function/"
sourceSubPath是包含源代码的镜像中源代码的绝对路径。
其他的改进和优化
除了上述的主要变化,该版本还有以下更改和增强:
- OpenFunction
- 核心 API
v1alpha2已弃用并删除 - 将 sha256 添加到服务镜像
- 将构建源信息添加到函数状态
- 将 Shipwright 升级到 v0.11.0
- 将 Knative 升级到 v0.32.0
- 将 Dapr 升级到 v1.8.3
- 将 Go 升级到 v1.18
- 核心 API
- functions-framework-java 发布 V1.0.0
- 在一个 pod 中支持多个函数
- 支持自动发布
- Builder
- 在一个 pod 中支持多个函数
- 将默认的 Java 框架版本更新为 1.0.0
- revision-controller 发布 v1.0.0(功能见上文)
以上就是 OpenFunction v1.0.0 的主要功能变化,在此十分感谢各位贡献者的参与和贡献。如果您正在寻找一款高效、灵活的云原生函数开发平台,那么 OpenFunction v1.0.0 将是您的绝佳选择。
了解更多关于 OpenFunction 和本次版本更新的信息,欢迎访问我们的官方网站和 Github 页面。
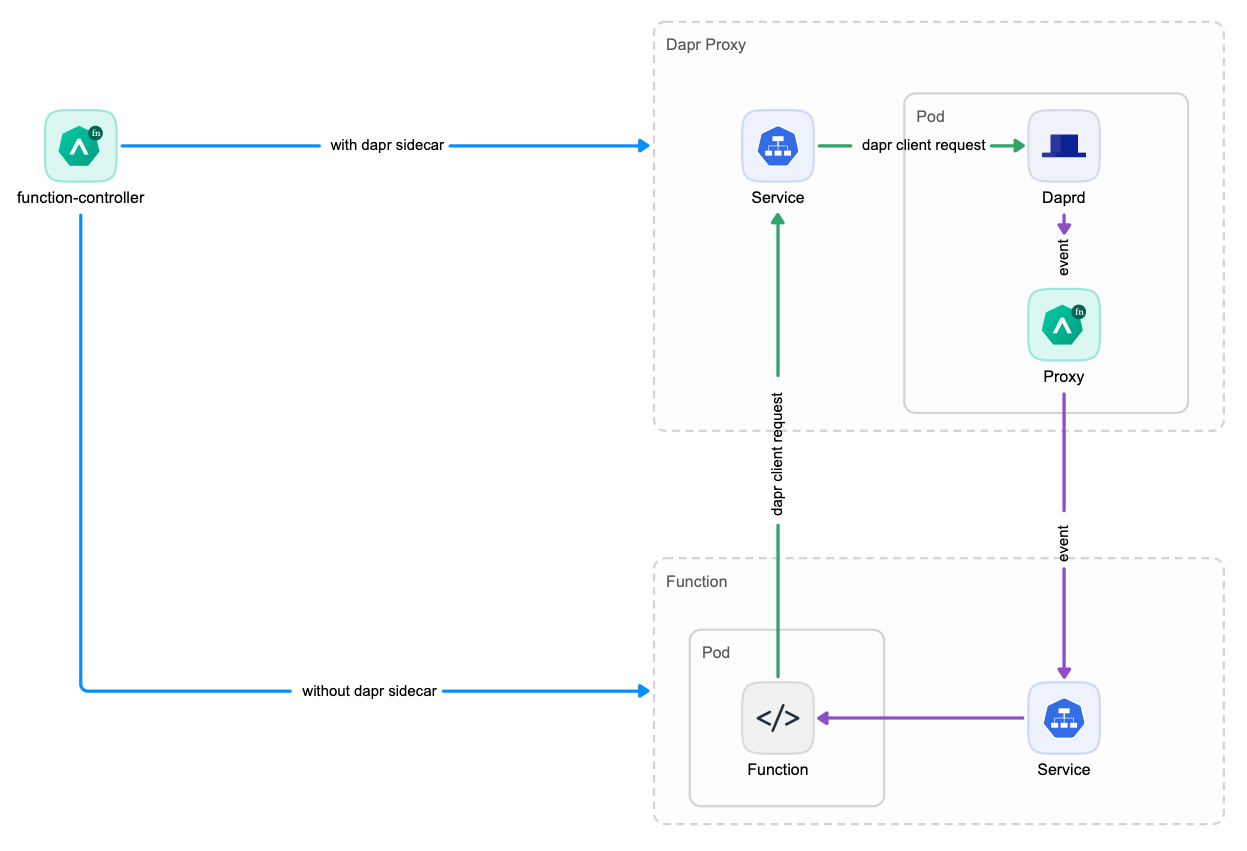
OpenFunction v0.8.0 发布:通过 Dapr Proxy 加速函数启动
相较于其他函数计算项目,OpenFunction 有很多独特的功能,其中之一便是通过 Dapr 与各种后端服务(BaaS)无缝集成。目前 OpenFunction 已经支持了 Dapr 的 pub/sub 和 bindings 构建模块,未来还会支持更多功能。截止到 v0.7.0,OpenFunction 与 BaaS 的集成还不算特别丝滑,需要在每个函数实例的 Pod 中注入一个 Dapr Sidecar 容器,这就会导致一个问题:整个函数实例的启动时间会受到 Dapr Sidecar 容器启动时间的影响,甚至 Dapr Sidecar 容器可能会比函数容器本身消耗的资源更多。
为了解决这个问题,OpenFunction 发布了 v0.8.0,引入了 Dapr Standalone 模式。
Dapr Standalone 模式
在新的 Dapr Standalone 模式中,无需为每个函数实例启动一个独立的 Dapr Sidecar 容器,而是为每个函数创建一个 Dapr Proxy 服务,这个函数的所有实例都会共享这个 Dapr Proxy 服务,大大减少了函数的启动时间。
如何选择 Dapr 服务模式
当然,除了新增的 Dapr Standalone 模式之外,您还可以继续选择使用 Dapr Sidecar 模式,建议您根据自己的实际业务来选择合适的 Dapr 服务模式。默认推荐使用 Dapr Standalone 模式,如果您的函数实例不需要频繁伸缩,或者由于一些其他原因无法使用 Dapr Standalone 模式,则可以使用 Dpar Sidecar 模式。
您可以通过在自定义资源 Function 中添加 spec.serving.annotations 来控制使用何种 Dapr 模式与 BaaS 集成,总共有两个 annotations:
openfunction.io/enable-dapr:可以设置为true或者false;openfunction.io/dapr-service-mode:可以设置为standalone或者sidecar。
当 openfunction.io/enable-dapr 设置为 true 时,可以调整 openfunction.io/dapr-service-mode 的值来选择不同的 Dapr 服务模式。
当 openfunction.io/enable-dapr 设置为 false 时,openfunction.io/dapr-service-mode 的值会被忽略,Dapr Standalone 模式与 Dapr Sidecar 模式都不会启用。
这两个 annotations 的默认值如下:
- 如果 Function 中没有添加
spec.serving.annotations配置块,并且 Function 中包含spec.serving.inputs和spec.serving.outputs配置块,openfunction.io/enable-dapr会被自动设置为true;否则openfunction.io/enable-dapr就会被设置为false。 openfunction.io/dapr-service-mode默认值是standalone。
示例:
apiVersion: core.openfunction.io/v1beta1
kind: Function
metadata:
name: cron-input-kafka-output
spec:
...
serving:
annotations:
openfunction.io/enable-dapr: "true"
openfunction.io/dapr-service-mode: "standalone"
template:
containers:
- name: function # DO NOT change this
imagePullPolicy: IfNotPresent
runtime: "async"
inputs:
- name: cron
component: cron
outputs:
- name: sample
component: kafka-server
operation: "create"
...
关于 v0.8.0 的更多发版细节可以参考 OpenFunction v0.8.0 的 Release Notes。
OpenFunction 0.7.0 发布: OpenFunction Gateway、多语言及 Helm 安装支持
OpenFunction 是一个开源的云原生 FaaS(Function as a Service,函数即服务)平台,旨在帮助开发者专注于业务逻辑的研发。在过去的几个月里,OpenFunction 社区一直在努力工作,为 OpenFunction 0.7.0 版本的发布做准备。今天,我们非常高兴地宣布 OpenFunction 0.7.0 已经正式发布了!感谢社区各位小伙伴的贡献和反馈!
OpenFunction 0.7.0 为您带来了许多新功能,包括新增 OpenFunction Gateway 作为同步函数入口、 新增 Java 和 NodeJS 同步函数和异步函数支持、新增 Helm 安装方式。 同时, 我们对 OpenFunction 依赖的组件都进行了版本升级。
OpenFunction Gateway
OpenFunction 从 0.5.0 开始采用 Kubernetes Ingress 来提供同步函数的统一入口,并且必须安装一个 nginx-ingress-controller。
在 OpenFunction 0.7.0 中,我们基于 Kubernetes Gateway API 实现了 OpenFunction Gateway 替代之前基于 Kubernetes Ingress 的 Domain 来访问同步函数的方法。
OpenFunction Gateway 提供了更强大、更灵活的函数网关,包含以下特性:
- 可以选择任意支持 Kubernetes Gateway API 的 Gateway 实现,如 Contour, Istio, Apache APISIX, Envoy Gateway 等。
- 可以选择安装默认的 Gateway 实现(Contour), 此时 OpenFunction 将自动创建 Kubernetes Gateway。OpenFunction 也可以使用您环境中现有的 Kubernetes Gateway,只需要您在 OpenFunction Gateway 中引用它即可。
- 可以自定义访问函数的模式,如基于
host的路由模式和基于path的路由模式,在您没有定义函数路由时 OpenFunction 默认提供基于host的路由模式来访问函数。 - 可以在函数路由部分自定义流量应该如何到达函数,OpenFunction 基于 Gateway API HTTPRoute 为您提供了强大的函数路由功能。
- 可以通过函数外部地址在集群外部访问函数,只需要在OpenFunction Gateway 中配置好集群外部可以访问的域名即可(同时支持 Magic DNS 和 Real DNS)。
- 现在 OpenFunction 将流量直接转发到 Knative Revision 而不再经过 Knative 的 Gateway。 如果不需要直接访问 Knative 服务, 您可以忽略 Knative Domain 相关的错误。
将来,OpenFunction 将支持在函数的不同版本之间进行流量分发。
多语言支持
OpenFunction 社区一直在努力完善多语言的支持:
Go
functions-framework-go 发布了 v0.4.0,支持在一个函数中定义多个子函数,并且可以通过不同的 Path 和 Method 分别调用。
Java
functions-framework-java 现在支持同步函数和异步函数。
NodeJS
functions-framework-nodejs 发布了 v0.5.0, 支持同步函数和异步函数,并且支持同步函数触发异步函数。
我们将在近期发布 functions-framework-nodejs v0.6.0,为您带来更多功能比如插件机制、与 SkyWalking 集成等。
OpenFunction 将会在后续版本支持更多语言如 Python、Dotnet 等。
Helm 安装 OpenFunction 及所有依赖组件
原来基于 CLI 安装的方法已弃用。
现在 OpenFunction 支持通过 Helm 安装 OpenFunction 及所有依赖的组件,相比原来通过 CLI 安装的方式更加云原生, 并且解决了部分用户访问 Google Container Registry(gcr.io)镜像受限的问题, 并且将长期维护。
TL;DR
helm repo add openfunction https://openfunction.github.io/charts/
helm repo update
helm install openfunction openfunction/openfunction -n openfunction --create-namespace
依赖组件升级
| Components | OpenFunction 0.6.0 | OpenFunction 0.7.0 |
|---|---|---|
| Knative Serving | 1.0.1 | 1.3.2 |
| Dapr | 1.5.1 | 1.8.3 |
| Keda | 2.4.0 | 2.7.1 |
| Shipwright | 0.6.1 | 0.10.0 |
| Tekton Pipelines | 0.30.0 | 0.37.0 |
OpenFunction 0.6.0 发布: FaaS 可观测性、HTTP 同步函数能力增强及更多特性
OpenFunction 是一个开源的云原生 FaaS(Function as a Service,函数即服务)平台,旨在帮助开发者专注于业务逻辑的研发。在过去的几个月里,OpenFunction 社区一直在努力工作,为 OpenFunction 0.6.0 版本的发布做准备。今天,我们非常高兴地宣布 OpenFunction 0.6.0 已经正式发布了!感谢社区各位小伙伴对新功能、增强功能和错误修复的各种帮助!
OpenFunction 0.6.0 为您带来了许多值得关注的功能,包括函数插件、函数的分布式跟踪、控制自动缩放、HTTP 函数触发异步函数等。同时,异步运行时定义也被重构了。核心 API 也已经从 v1alpha1 升级到 v1beta1。
面向 Serverless 函数的分布式追踪
当试图了解和诊断分布式系统和微服务时,最有效的方法之一是通过追踪函数的调用链路。分布式追踪为 Serverless 函数提供了一个关于消息流动和分布式事务监控方式的整体视图。OpenFunction 团队与 Apache SkyWalking 社区合作,增加了 FaaS 的可观测性,使得您可以在 SkyWalking UI 上通过图表来可视化 Serverless 函数的依赖关系并追踪函数的调用。
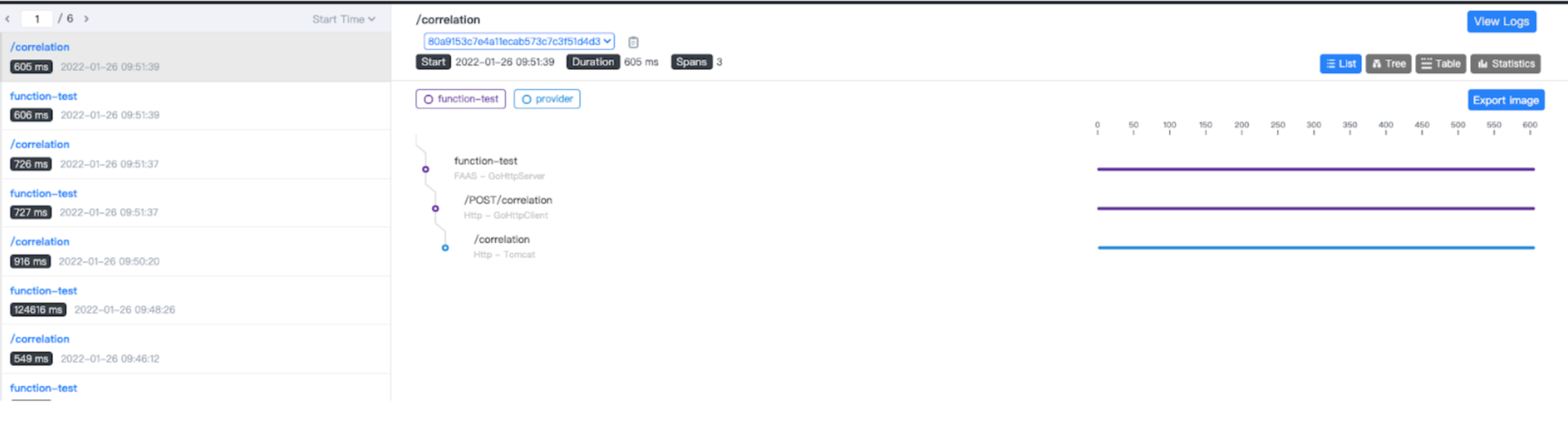
将来,OpenFunction 将在日志、指标和追踪方面为 Serverless 功能增加更多的功能。您将能够使用 Apache SkyWalking 和 OpenFunction,为您的 Serverless 工作负载建立一个开箱即用的全栈 APM(Application Performance Monitoring)。此外,OpenFunction 将支持 OpenTelemetry,帮助您利用 Jaeger 或 Zipkin 作为分布式追踪的其它选项。
支持 Dapr 发布/订阅和绑定(Binding)
Dapr Binding 允许您使用来自外部系统的事件触发您的应用程序或服务,或与外部系统对接。OpenFunction 0.6.0 为其同步函数增加了 Dapr 输出绑定(Output Binding),使异步函数通过 HTTP 同步函数进行触发成为了可能。例如,由 Knative 运行时支持的同步函数现在可以与由 Dapr 输出绑定或 Dapr Pub/Sub 中间件 进行交互,异步函数将被同步函数发送的事件所触发。您可以通过这个 指南 获得快速入门样例。
异步函数则引入了 Dapr Pub/Sub,提供一个平台无关的 API 来发送和接收消息。一个典型的用例是,您可以利用同步函数来接收纯 JSON 或 Cloud Event 格式的事件,然后将收到的事件发送到 Dapr 输出绑定或 Pub/Sub 组件,比如是一个消息队列(如 Kafka、NATS Streaming、GCP PubSub)。最后,异步函数可以从消息队列中被触发。您可以通过这个 指南 获得快速入门样例。
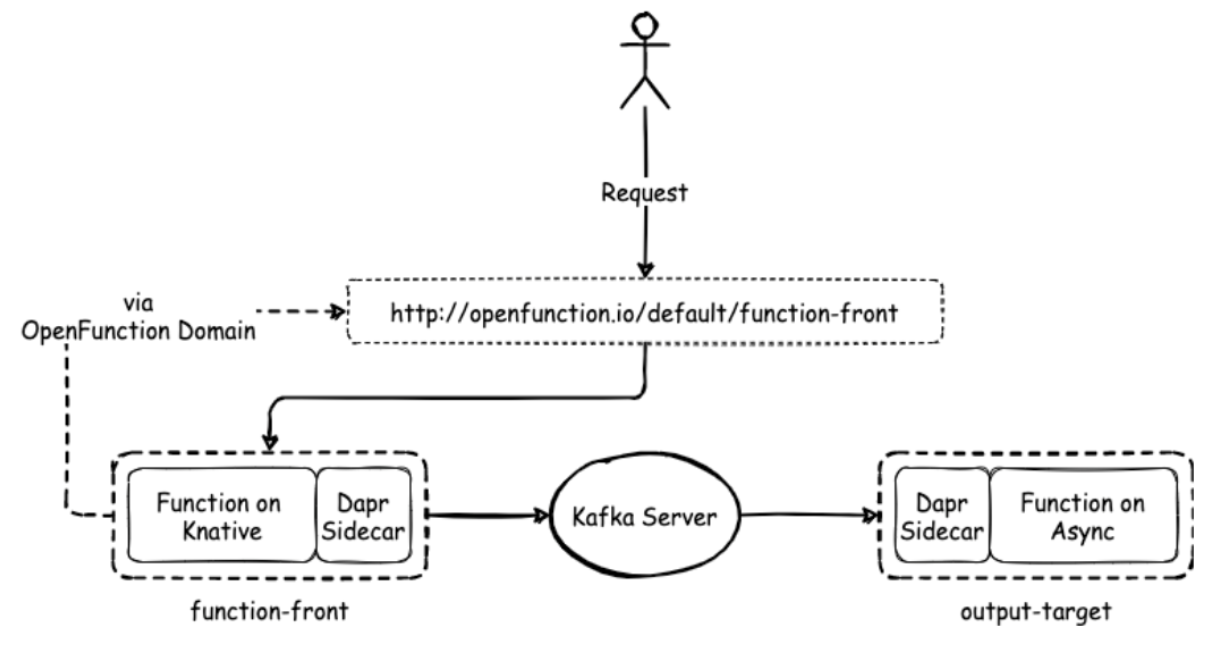
函数的自动伸缩行为控制
OpenFunction 0.6.0 集成了 KEDA ScaledObject 规范,用于定义 KEDA 应该如何扩展您的应用程序以及触发器是什么。您只需要在 OpenFunction 函数的 CRD 中定义伸缩下限和上限,而无需改变您的代码。
同时,OpenFunction 社区也在开发控制并发性和同时请求数的能力,它继承了 Dapr 和 Knative 的定义。分布式计算的一个典型用例是只允许一定数量的请求同时执行。您将能够控制多少个请求和事件将同时调用您的应用程序。这个功能将在下一个版本中得到完全支持,敬请期待!如果您对这个功能感兴趣,请查看官方代码仓库中的 讨论,了解详细的背景。
在实践中学习
OpenFunction 的创始人霍秉杰先生在 Dapr 社区会议上介绍了 OpenFunction 0.6.0 的两个典型用例:
- HTTP trigger for asynchronous functions with OpenFunction and Kafka
- Elastic Kubernetes log alerts with OpenFunction and Kafka
您可以观看下面这两段视频,并按照实践指南进行练习。
您还可以从 发布说明 中了解更多关于 OpenFunction 0.6.0 的信息。参照 快速入门 和 样例 开始使用 OpenFunction。
Release v0.4.0
@wanjunlei wanjunlei 发布于 2021.10.19
版本地址:v0.4.0
版本说明:
特性
改善增强
- Update dependent Dapr version to v1.3.1. #123
- Update dependent Tekton pipeline version to 0.28.1. #131
- Update dependent Knative serving version to 0.26.0. #131
- Update dependent Shipwright build version to 0.6.0. #131
- Update go version to 1.16. #131
- Now Function supports environment variables with commas. #131
修复
- Fix bug rerun serving failed. #132
文档
- Use installation script to deploy OpenFunction and deprecate the installation guide. #122
OpenFunction/website
- Add OpenFunction Website. #1
OpenFunction/cli
- Add OpenFunction CLI. #11
OpenFunction/builder
- Upgrade the functions-framework-go from v0.0.0-20210628081257-4137e46a99a6 to v0.0.0-20210922063920-81a7b2951b8a. #17
- Add Ruby builder. #11
OpenFunction/functions-framework-go
- Supports multiple input sources && Replace int return with ctx.Return. #13
OpenFunction/functions-framework-nodejs
- Support OpenFunction type function. #7
OpenFunction/events-handlers
- Add handler functions. #7
感谢
感谢为 v0.4.0 版本的作出贡献的贡献者们!
@wanjunlei @benjaminhuo @tpiperatgod @linxuyalun @penghuima @lizzzcai
Release v0.3.1
@wanjunlei wanjunlei 发布于 2021.8.27
版本地址:v0.3.1
版本说明:
- Delete the old serving CR only after the new serving CR is running. #107
Release v0.3.0
@tpiperatgod tpiperatgod 发布于 2021.8.19
版本地址:v0.3.0
版本说明:
- Add OpenFunction Events: OpenFunction’s own event management framework. #78 #83 #89 #90 #99 #100 @tpiperatgod
- Support using Shipwright as Builder backend to build functions or apps. #82 #95 @wanjunlei
- Build and serving can be launched separately now. #82 #95 @wanjunlei
- Support running an application (container image) as a serverless workload directly. #82 #95 @wanjunlei
Release v0.2.0
@benjaminhuo benjaminhuo 发布于 2021.5.17
版本地址:v0.2.0
版本说明:
- Support OpenFunctionAsync serving runtime(backed by Dapr + KEDA + Deployment/Job)
- Functions framework supports async function now
- Customized go function framework & builders for both Knative and OpenFunctionAsync serving runtime
Release v0.1.0
@benjaminhuo benjaminhuo 发布于 2021.5.17
版本地址:v0.1.0
版本说明:
- Add Function, Builder, and Serving CRDs and corresponding controllers
- Support using existing function framework & buildpacks such as Google Cloud Functions to build functions
- Support Tekton and Cloud Native Buildpacks as Builder backend
- Support Knative as Serving backend
- Optimize and localize existing function framework & buildpacks
技术博客
快速上手 OpenFunction Node.js 异步函数服务开发
10 多天前,“OpenFunction 顺利通过了云原生计算基金会 CNCF 技术监督委员会(TOC)的投票,正式进入 CNCF 沙箱(Sandbox)托管”。作为 OpenFunction 社区的一份子,非常期待能有更多开发者和合作伙伴参与到项目中来,共同建设和发展社区,“使 Serverless 函数与应用运行更简单”!同时,作为 Node.js 函数框架(Function Framework)目前的 Maintainer 之一,也想借此机会和大家分享一下 Node.js 函数框架最近的研发进展,特别是在 0.4.1 版本中已经实现的对于异步函数的支持。
本文将从以下几方面来介绍 Node.js 函数框架目前的研发进展和之后的工作展望。
同步函数当前状态简述
一句话简述:支持 Express 形态的 “请求-响应” 函数调研,同时也支持接收 CloudEvents 标准定义的事件数据。
在 0.4.1 版本中,我们基于 GCP(Google Cloud Platform)Function Framework 对 Node.js 函数框架了进行了重建,在同步函数方面基本完整的保留了 GCP Node.js 函数框架的现有能力。
首先,最经典的 Express 形态的函数签名是必须支持的,这也是我们日常进行同步函数开发的主要形态。
/**
* Send "Hello, World!"
* @param req https://expressjs.com/en/api.html#req
* @param res https://expressjs.com/en/api.html#res
*/
export const helloWorld = (req, res) => {
res.send('Hello, World!');
};
- 您可以参考 Quickstart: “Hello, World” on your local machine 在本地编写并运行同步函数,并参考 此样例 中的 Function 资源描述来在 Kubernetes 中进行部署和运行。
- 关于 OpenFunction 框架的基础使用方式,您可以参考 开源函数计算平台 OpenFunction 保姆级入门教程 文中的细节。
其次,CloudEvents 作为云原生领域日益重要的事件数据(Event Data)描述标准,我们的同步函数也已支持接收 CloudEvents 标准定义的事件数据。您可以参考 此文档 在本地构建函数并测试 CloudEvents 的接收处理。
const functions = require('@openfunction/functions-framework');
functions.cloudEvent('helloCloudEvents', (cloudevent) => {
console.log(cloudevent.specversion);
console.log(cloudevent.type);
console.log(cloudevent.source);
console.log(cloudevent.subject);
console.log(cloudevent.id);
console.log(cloudevent.time);
console.log(cloudevent.datacontenttype);
});
同步函数的版本迭代计划
OpenFunction 0.6.0 为其同步函数增加了 Dapr 输出绑定(Output Binding),使异步函数通过 HTTP 同步函数进行触发成为了可能(例如由 Knative 运行时支持的同步函数现在可以与由 Dapr 输出绑定或 Dapr Pub/Sub 中间件进行交互,异步函数将被同步函数发送的事件所触发)。我们将在下一个 Node.js 函数框架的迭代版本中提供此项同步函数增强能力的支持。
异步函数快速上手指北
一句话简述:现已支持通过 Node.js 异步函数接收和调用 Dapr 输入/输出绑定(Input/Output Binding)和发布/订阅(Pub/Sub)构建块的能力。
示例环境准备
为了方便同时展示 “输入输出绑定” 和 “发布订阅” 这两个功能,我们在以下两个示例中采用了 MQTT 这个同时支持这两种异步消息使用模式的组件,所以需要先在 Kubernetes 环境中部署一个 MQTT 中间件服务。
我们在这里选用 EMQ 公司的开源 MQTT 中间件 EMQX 作为我们示例运行基础组件,它支持通过 Helm 方式进行部署(参见 通过 Helm3 在 Kubernetes 上部署 EMQX 4.0 集群):
helm repo add emqx https://repos.emqx.io/charts
helm repo update
$ helm search repo emqx
NAME CHART VERSION APP VERSION DESCRIPTION
emqx/emqx 4.4.3 4.4.3 A Helm chart for EMQX
emqx/emqx-ee 4.4.3 4.4.3 A Helm chart for EMQ X
emqx/emqx-operator 1.0.4 1.1.6 A Helm chart for EMQX Operator Controller
helm install emqx emqx/emqx --set replicaCount=1 --set service.type=NodePort
部署完成后,您可用检查 EMQX StatefulSet 和 Service 的状态,请确保它们都进入了运行状态:
$ kubectl get sts -o wide
NAME READY AGE CONTAINERS IMAGES
emqx 1/1 11d emqx emqx/emqx:4.4.3
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
emqx NodePort 10.233.52.80 <none> 1883:32296/TCP,8883:32089/TCP,8081:32225/TCP,8083:32740/TCP,8084:31394/TCP,18083:30460/TCP 11d
emqx-headless ClusterIP None <none> 1883/TCP,8883/TCP,8081/TCP,8083/TCP,8084/TCP,18083/TCP,4370/TCP 11d 31d
记住这里 1883端口对应的 NodePort 端口 32296,我们会在后面的示例实验过程中用到(NodePort 在每次部署的时候都会变化,以实际部署时为准)。
同时您可用通过访问 EMQX 自带的 Dashboard 来确认部署成功(端口:18083对应的 NodePort 端口;用户名:admin;默认密码:public)。
关于 MQTT 协议以及 EMQ X Broker 中间件的行业应用,可以参见我们在 KubeSphere 社区直播中的分享《 MQTT 及车联网场景应用 》。
为了方便后续执行 MQTT 消息的发布和监测,我们可以下载同样来自于 EMQ 公司的 MQTT X 桌面客户端工具备用。您也可以使用任意 MQTT 客户端来完成相关操作。
示例函数编写
下面我们编写一个非常简单的异步函数作为示例,整个项目只需要两个文件:index.mjs,package.json。
// 同步函数入口
export const tryKnative = (req, res) => {
res.send(`Hello, ${req.query.u || 'World'}!`);
};
// 异步函数入口
export const tryAsync = (ctx, data) => {
console.log('Data received: %o', data);
ctx.send(data);
};
我们先来看 index.mjs 这个主文件,其中有两个关键点需要留意:
- 异步函数签名:异步函数使用
function (ctx, data)作为函数签名,其中:ctx包含了执行的 上下文数据,同时具有一个send(data, ouput?)方法用于向 Dapr 全部(或特定)的输出绑定或发布通道发送数据data是从 Dapr 的输入绑定或订阅通道接收的数据
- 主文件可以同时包含同步和异步函数入口:这一点是 Go 函数框架做不到的,后文会介绍如何使用这个特性(如果大家熟悉 Node.js 动态脚本语言的性质就不难理解)
{
"main": "index.mjs",
"scripts": {
"start": "functions-framework --target=tryKnative"
},
"dependencies": {
"@openfunction/functions-framework": "^0.4.1"
}
}
元数据文件 package.json 可以定义的非常简单,核心就是两部分:
main:指定主函数文件(注意从 Node.js 15.3.0 开始,ES Modules 就已可以稳定使用,因此推荐直接使用.mjs后缀来标记 ESM 格式文件)scripts``dependencies:这些主要是为了方便本地测试而准备的,非必需,但推荐也安排上- 关于
functions-framework命令行的可惜参数,可以参考 Configure the Functions Framework
- 关于
示例镜像准备
OpenFunction 自带 Shipwirght / Tekton 可以实施 Cloud Native Buildpacks 的 OCI 镜像打包,本地打包更适合网络环境比较糟糕(或 GitHub 访问困难)的集群。
这里我们推荐使用跨平台但 Pack 工具来实施本地打包,安装之后的使用命令也非常简单(如下所示),镜像生成后推送至您指定的仓库备用。
pack build -B openfunction/builder-node:v2-16.13 -e FUNC_NAME=tryKnative -p src <image-repo>/<image-name>:<tag>
-B openfunction/builder-node:v2-16.13:必填,16.13 是目前 OpenFunction 可以使用的最新的 Node.js 环境 Builder,未来会迭代更新的版本(撰文是最新版本为 18)-e FUNC_NAME=tryKnative:必填,设置默认的入口函数,建议选择一个最基础的同步函数作为入口,不妨碍后续异步函数使用(详见后文)-p src:默认是使用当前目录,但建议把源文件和 OpenFunction CR 文件分层或分目录存在,用通过设置文件路径来使用
示例:MQTT 输入输出绑定
任务目标:我们的服务需要从
in主题接收一条输入消息,并将其作为输出数据发送给out主题消息通道中。
万事俱备,让我们先来看如何使用异步函数联通 MQTT 的输入输出,下面是一个 Function CR 的示例(参见 Function CRD定义)。
apiVersion: core.openfunction.io/v1beta1
kind: Function
metadata:
name: sample-node-async-bindings
spec:
version: v2.0.0
image: '<image-repo>/<image-name>:<tag>'
serving:
# default to knative
runtime: async
annotations:
# default to "grpc"
dapr.io/app-protocol: http
template:
containers:
- name: function
imagePullPolicy: Always
params:
# default to FUNC_NAME value
FUNCTION_TARGET: tryAsync
inputs:
- name: mqtt-input
component: mqtt-in
outputs:
- name: mqtt-output
component: mqtt-out
operation: create
bindings:
mqtt-in:
type: bindings.mqtt
version: v1
metadata:
- name: consumerID
value: '{uuid}'
- name: url
value: tcp://admin:public@emqx:1883
- name: topic
value: in
mqtt-out:
type: bindings.mqtt
version: v1
metadata:
- name: consumerID
value: '{uuid}'
- name: url
value: tcp://admin:public@emqx:1883
- name: topic
value: out
让我们逐一解读一下 OpenFunction Serving 阶段的几个重要配置项及其内容:
serving.runtime:异步函数使用async,默认值是knative指代同步函数serving.annoations:必须设置注释dapr.io/app-protocol: http,原因是目前 Node.js 函数框架是通过 HTTP 与 Dapr Sidecar 进行双向连接的,而 OpenFunction 默认使用 gRPC 协议和函数框架通信(虽然 Dapr 默认是 HTTP,有点绕 🤦♂️)serving.params:通过这个入口可以设置运行时的环境变量,于是我们便可以通过FUNCTION_TARGET: tryAsync在此动态指定函数入口,可以是任一已被模块导出的函数serving.inputs/outputs:输入/输出绑定及其操作的设置,参见 Function CRD - DaprIO 的各个可用字段描述serving.bindings:这部分定义 Dapr 的绑定组件,每个组件对象的键(如mqtt-in``mqtt-out)需要被serving.inputs/outputs准确引用,而值的部分则完全参考 Dapr 官方文档的 Component specs - Bindings 来填写即可(注意当前 OpenFunction 0.6.0 对应使用的 Dapr 版本为 1.5.1)
部署并确认函数运行
应用该 YAML 后,可查看函数及其对应的 Pod 状态:
$ kubectl apply -f async-bindings.yaml
function.core.openfunction.io/sample-node-async-bindings created
$ kubectl get fn
NAME BUILDSTATE SERVINGSTATE BUILDER SERVING URL AGE
sample-node-async-bindings Skipped Running serving-8f7xc 140m
$ kubectl get po
NAME READY STATUS RESTARTS AGE
...
serving-8f7xc-deployment-v200-l78xc-564c6b5bf7-vksg7 2/2 Running 0 141m
进而可以进一步查看 Pod 中 function 函数容器的日志,可以得到如下启动信息:
$ kubectl logs -c function serving-8f7xc-deployment-v200-l78xc-564c6b5bf7-vksg7
2022-05-04T13:06:18.505Z common:options ℹ️ Context loaded: <...>
[Dapr-JS] Listening on 8080
[Dapr API][PubSub] Registering 0 PubSub Subscriptions
[Dapr-JS] Letting Dapr pick-up the server (Maximum 60s wait time)
[Dapr-JS] - Waiting till Dapr Started (#0)
[Dapr API][PubSub] Registered 0 PubSub Subscriptions
[Dapr-JS] Server Started
使用 MQTT X 测试输入输出
打开 MQTT X 并使用之前记录的 EMQX 服务 NodePort 端口 32296 创建连接,并添加一个 out/#的订阅。之后向 in主题发送内容 {"msg": "hello"}即可得到如下界面效果:
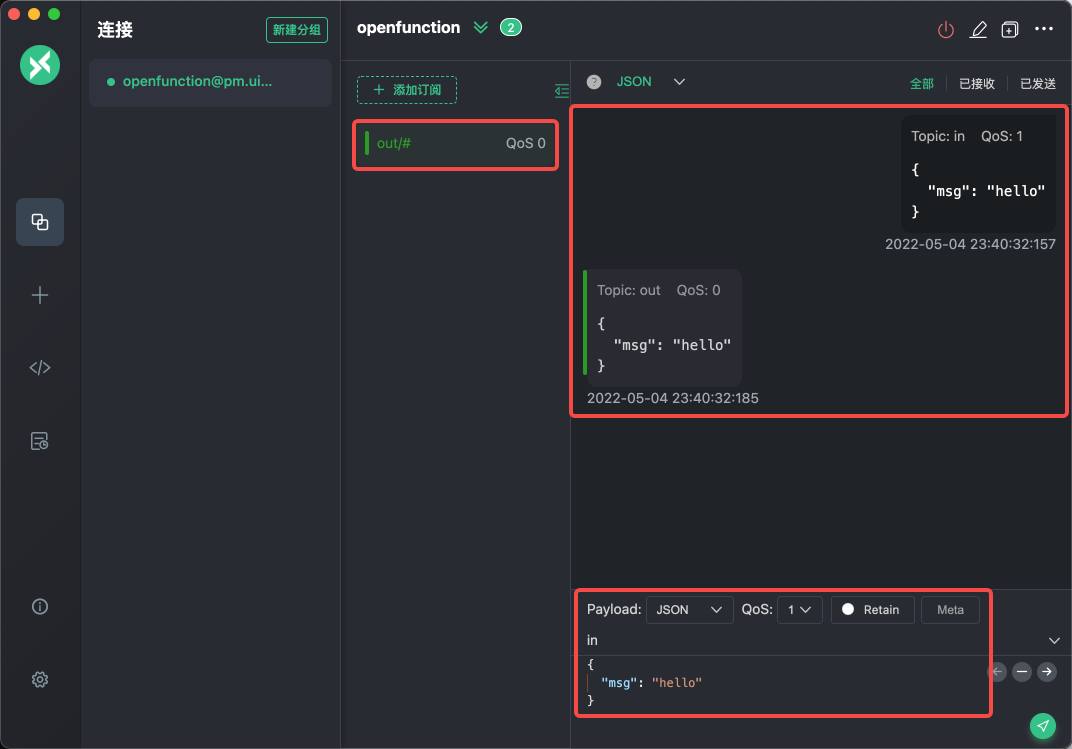 如上图所示,可以看到消息向
如上图所示,可以看到消息向 in 主题发送,通过异步函数的转发,在 out 主题中被接收。也可以进一步从函数的容器日志中查看到输出 Data received: { msg: 'hello' }。
$ kubectl logs -c function serving-8f7xc-deployment-v200-l78xc-564c6b5bf7-vksg7
2022-05-04T13:06:18.505Z common:options ℹ️ Context loaded: <...>
[Dapr-JS] Listening on 8080
[Dapr API][PubSub] Registering 0 PubSub Subscriptions
[Dapr-JS] Letting Dapr pick-up the server (Maximum 60s wait time)
[Dapr-JS] - Waiting till Dapr Started (#0)
[Dapr API][PubSub] Registered 0 PubSub Subscriptions
[Dapr-JS] Server Started
Data received: { msg: 'hello' }
示例:MQTT 订阅及发布
任务目标:我们的服务需要订阅
sub主题,并将接收到的消息发布到pub主题中。(请特别留意本示例和前一示例的异同)
发布订阅 MQTT 的功能在 OpenFunction 和 Dapr 框架的支持下也是非常简单,Function 的定义几乎和上一部分的绑定一样,下面我们挑选其中有变化的部分加以说明:
apiVersion: core.openfunction.io/v1beta1
kind: Function
metadata:
name: sample-node-async-pubsub
spec:
version: v2.0.0
image: '<image-repo>/<image-name>:<tag>'
serving:
# default to knative
runtime: async
annotations: ...
template: ...
params: ...
inputs:
- name: mqtt-sub
component: mqtt-pubsub
topic: sub
outputs:
- name: mqtt-pub
component: mqtt-pubsub
topic: pub
pubsub:
# Dapr MQTT PubSub: https://docs.dapr.io/reference/components-reference/supported-pubsub/setup-mqtt/
mqtt-pubsub:
type: pubsub.mqtt
version: v1
metadata:
- name: consumerID
value: '{uuid}'
- name: url
value: tcp://admin:public@emqx:1883
- name: qos
value: 1
serving.inputs/outputs:这部分基本和绑定示例中的一样,需要特别注意的是topic字段是发布订阅模式下专属的一个字段,用于定义发布订阅的主题serving.pubsub:这部分和serving.bindings也基本类似,这部分定义 Dapr 的发布订阅组件,每个组件对象的键(如mqtt-pubsub)需要被serving.inputs/outputs准确引用,而值的部分则完全参考 Dapr 官方文档的 Component specs - Pub/sub brokers 来填写即可
部署并确认函数运行
这部分和上一示例中的步骤基本一致,我们需要确仍 Pod 的运行状态及日志,特别是从函数日志上可以清新的看到如 Registered 1 PubSub Subscriptions的输出。
$ kubectl apply -f async-pubsub.yaml
function.core.openfunction.io/sample-node-async-pubsub created
$ kubectl get fn
NAME BUILDSTATE SERVINGSTATE BUILDER SERVING URL AGE
sample-node-async-bindings Skipped Running serving-8f7xc 16h
sample-node-async-pubsub Skipped Running serving-2qfkl 16h
$ kubectl get po
NAME READY STATUS RESTARTS AGE
...
serving-2qfkl-deployment-v200-6cshf-57c8b5b8dd-ztmbf 2/2 Running 0 16h
serving-8f7xc-deployment-v200-l78xc-564c6b5bf7-vksg7 2/2 Running 0 16h
$ kubectl logs -c function serving-2qfkl-deployment-v200-6cshf-57c8b5b8dd-ztmbf
2022-05-05T05:14:03.094Z common:options ℹ️ Context loaded: <...>
[Dapr-JS] Listening on 8080
[Dapr API][PubSub] Registering 1 PubSub Subscriptions
[Dapr-JS] Letting Dapr pick-up the server (Maximum 60s wait time)
[Dapr-JS] - Waiting till Dapr Started (#0)
[Dapr API][PubSub] Registered 1 PubSub Subscriptions
[Dapr-JS] Server Started
使用 MQTT X 测试输入输出
在 MQTT X 中我们新建一个 pub/# 的订阅,之后向 sub 主题发布一段 JSON,可以得到如下的收发数据界面效果。
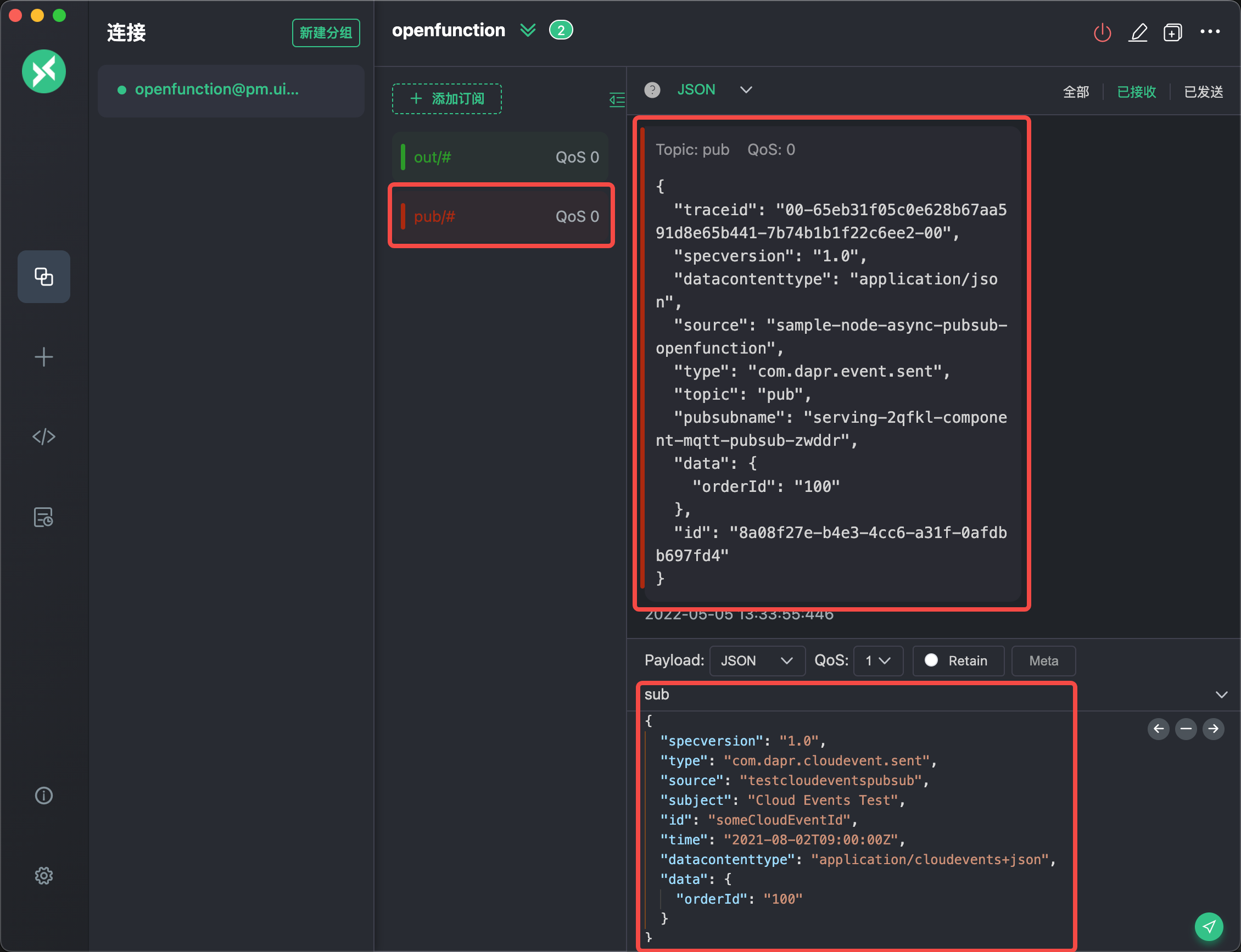
大家可能已经注意到了,我们在发布订阅中发送的数据看似 “非常复杂”?没错!因为 Dapr 的发布和订阅功能默认都是使用 CloudEvents 数据格式来进行数据传输的(上图中的样例数据参见官方文档的 Sending a custom CloudEvent 部分的示例)。
但是,对于我们的函数框架,我们收到的数据是 CloudEvent 中被解析出来的 data 部分:如本例中的 Data received: { orderId: '100' } —— 也就是说 Dapr Sidecar 会处理数据负载的装箱和拆箱,对于函数开发者来说可以 “忽略” CloudEvent 数据包这部分的结构。
$ kubectl logs -c function serving-2qfkl-deployment-v200-6cshf-57c8b5b8dd-ztmbf
2022-05-05T05:14:03.094Z common:options ℹ️ Context loaded: <...>
[Dapr-JS] Listening on 8080
[Dapr API][PubSub] Registering 1 PubSub Subscriptions
[Dapr-JS] Letting Dapr pick-up the server (Maximum 60s wait time)
[Dapr-JS] - Waiting till Dapr Started (#0)
[Dapr API][PubSub] Registered 1 PubSub Subscriptions
[Dapr-JS] Server Started
Data received: { orderId: '100' }
以上两个示例的完整代码(含 Function Build 部分的参考 YAML)可以参见 OpenFunction 的在线样例库中的 Node.js 样例 部分。
下一阶段的展望
OpenFunction 0.6.0 的发布带来了许多值得关注的功能,包括函数插件、函数的分布式跟踪、控制自动缩放、HTTP 函数触发异步函数等。同时,异步运行时定义也被重构了。核心 API 也已经从
v1alpha1升级到v1beta1。
除了前文提到的 “HTTP 函数触发异步函数” 即将在下一个版本中进行实现。还有两个重要的功能也是下阶段的重点:
- 函数插件:在 OpenFunction 的函数 CRD 中,允许用户定义在主体(Main)函数运行前/后执行的插件(Plugin)函数,并在函数运行时依靠函数框架保障插件的运行及其运行关系。您可以参见 此案例 中的插件定义来初步了解。
- 函数可观测:第二项重要的功能是 使用 SkyWalking 为 OpenFunction 提供可观测能力。类似的,这些功能也需要函数框架的支持来使得 SkyWalking 可以正确的构建函数关系和追踪链路。
目前 OpenFunction Go 语言函数框架是完整支持上述两项功能的,我们期望在后续 Node.js 函数框架中也使能这两项能力。我们也已经在今年的 开源之夏 活动中也开放了这些内容作为 项目选题,非常欢迎社区的同学们(字面意义的同学们)参与进来,一起共建我们的 OpenFunction 生态,让 Serverless 函数与应用运行更简单!
OpenFunction 成为 CNCF 沙箱项目,使 Serverless 函数与应用运行更简单

2022 年 4 月 27 日,青云科技容器团队开源的函数即服务(FaaS: Function-as-a-Service)项目 OpenFunction 顺利通过了云原生计算基金会 CNCF 技术监督委员会(TOC)的投票,正式进入 CNCF 沙箱(Sandbox)托管。这就意味着 OpenFunction 得到了云原生开源社区的认可,同时通过进入 Sandbox 可以进一步保障项目的中立性,开发者以及合作伙伴等都可以参与项目建设,共同打造新一代开源函数计算平台。
这已经是青云科技容器团队发起的第三个进入 CNCF 的项目了。早在 2021 年 7 月份青云科技就将 Fluent Operator 项目捐给 Fluent 社区成为 CNCF 子项目,大大降低了 Fluent Bit 和 Fluentd 用户的使用门槛;同年 11 月份,负载均衡器插件 OpenELB 加入 CNCF Sandbox,帮助私有化环境更便捷地对外暴露服务。
目前可以在 CNCF Landscape 的 Serverless 版块中找到 OpenFunction 项目。

项目介绍
OpenFunction 是一个现代化的函数即服务(FaaS: Function-as-a-Service)项目,它能够帮助开发者专注于他们的业务逻辑,而不必担心底层运行环境和基础设施。用户只需提交一段代码,就可以生成事件驱动的、动态伸缩的 Serverless 工作负载。
OpenFunction 引入了很多非常优秀的开源技术栈,包括 Knative、Tekton、Shipwright、Dapr、KEDA 等,这些技术栈为打造新一代开源函数计算平台提供了无限可能:
- Shipwright 可以在函数构建的过程中让用户自由选择和切换镜像构建的工具,并对其进行抽象,提供了统一的 API;
- Knative 提供了优秀的同步函数运行时,具有强大的自动伸缩能力;
- KEDA 可以基于更多类型的指标来自动伸缩,更加灵活;
- Dapr 可以将不同应用的通用能力进行抽象,减轻开发分布式应用的工作量。
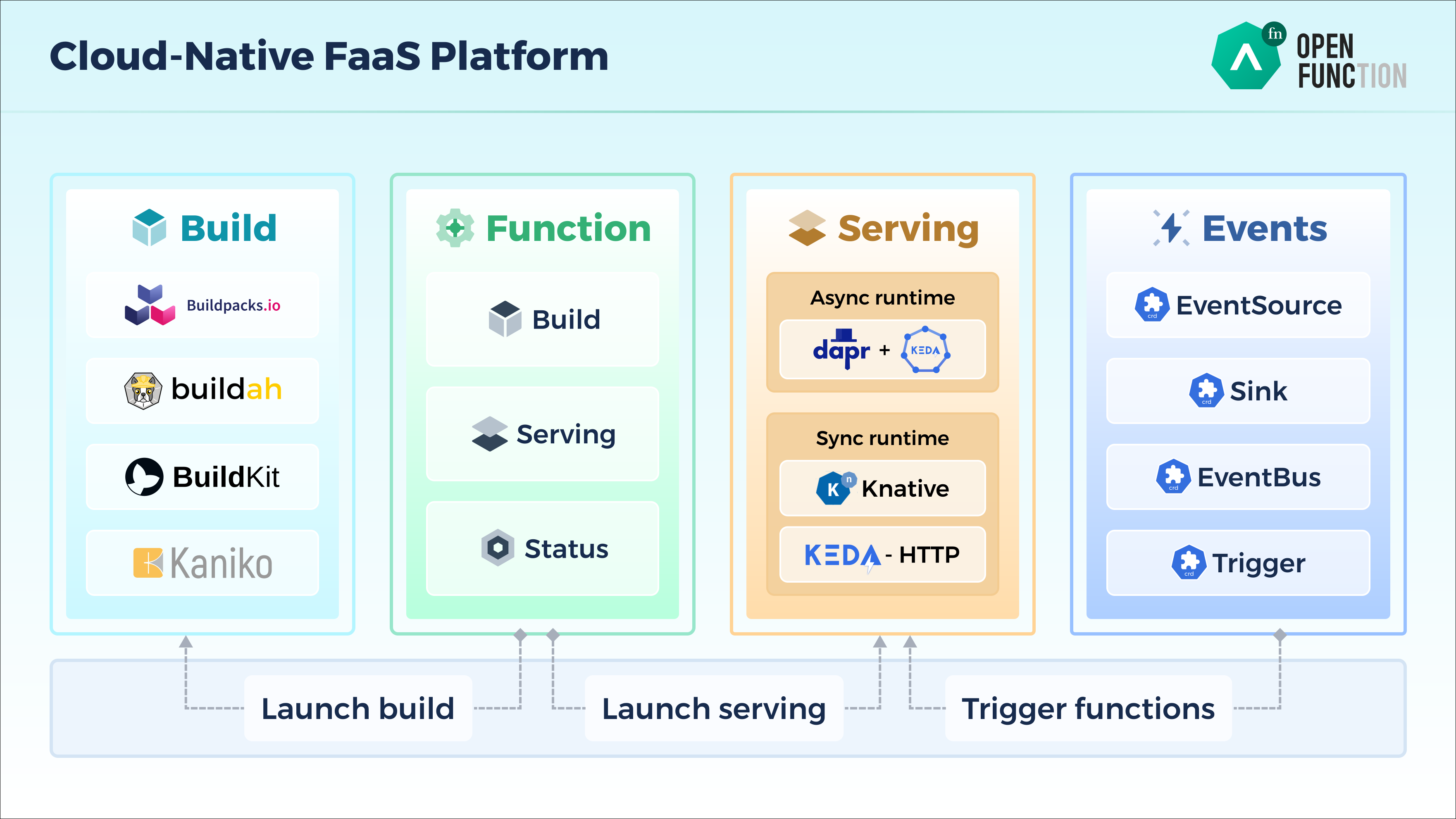
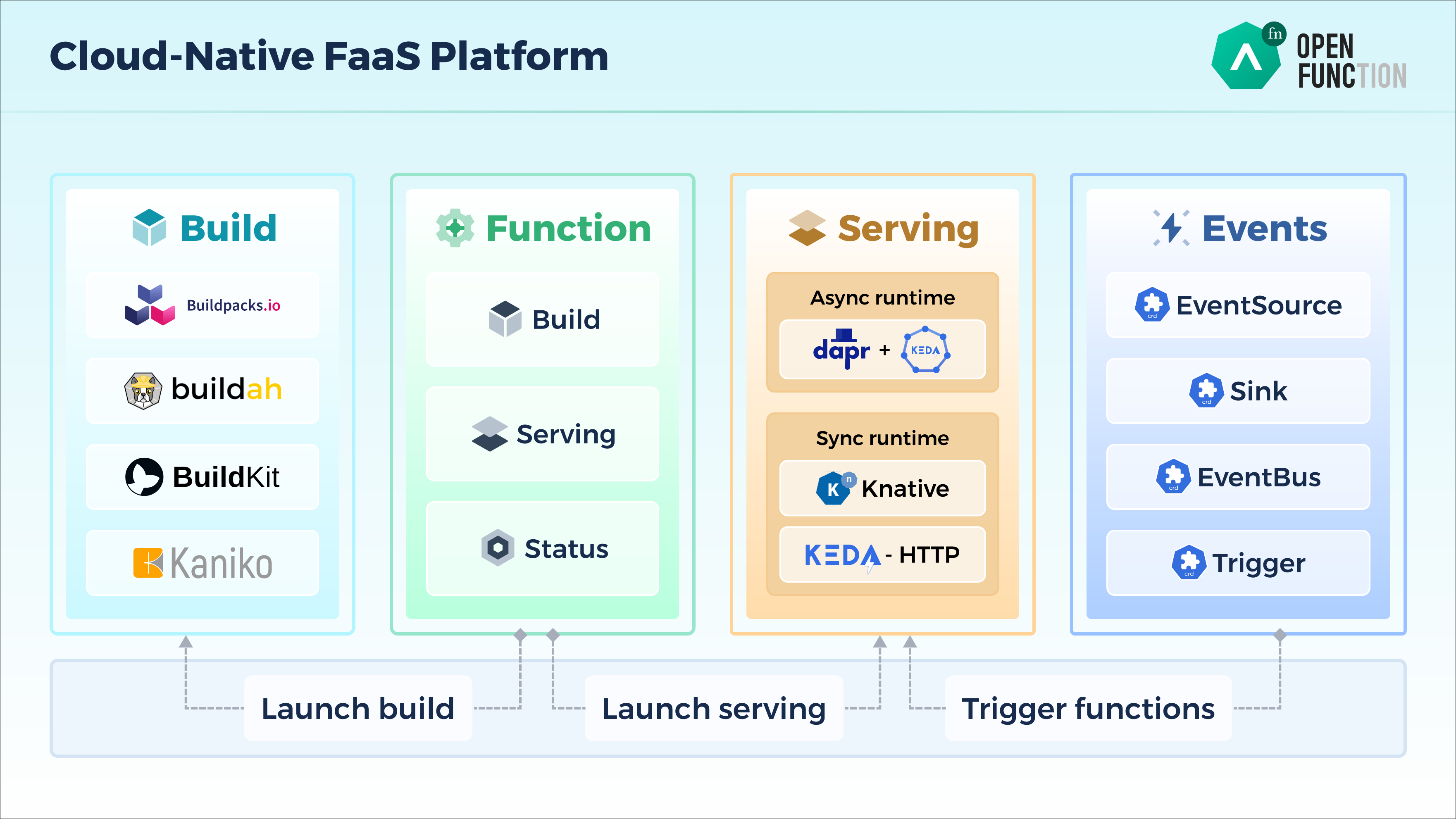
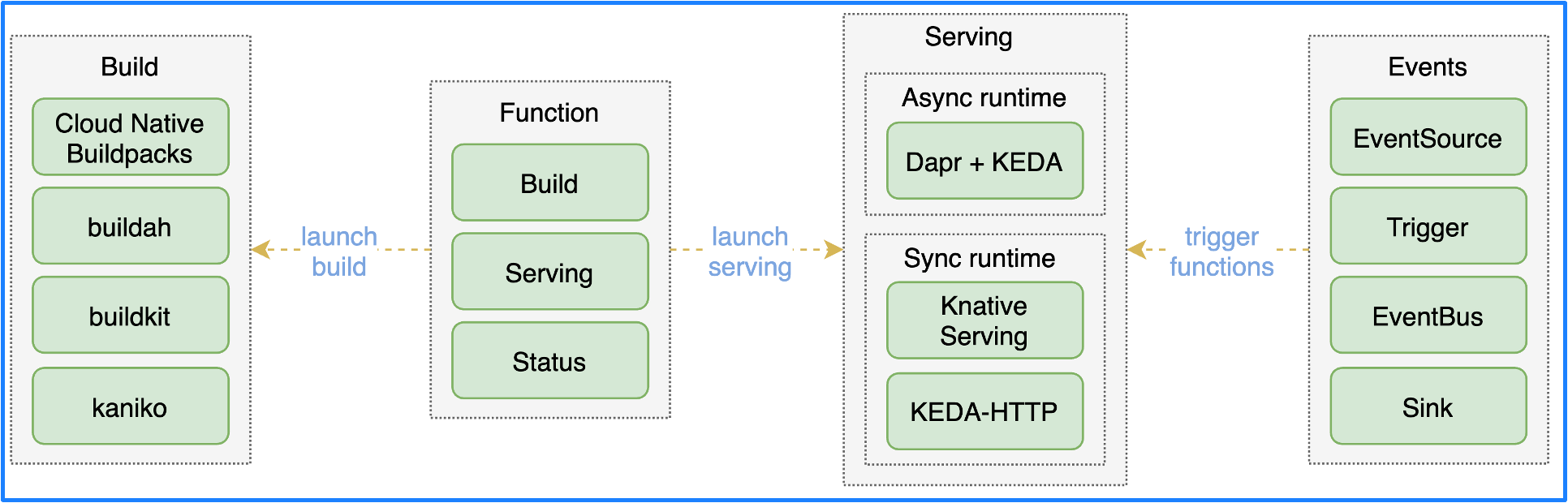
从架构图上可以看出,OpenFunction 包含了 4 个核心组件:
- Function : 用户和函数打交道(函数的增删改查)的唯一入口,包含了函数的 Build 和 Serving 阶段的全部定义;
- Build : 用户创建 Function 后,Function 生成相应的 Builder,用户无须手动创建。 Builder 通过 Shipwright 选择不同的镜像构建工具 Cloud Native Buildpacks, buildah, BuildKit, Kaniko, 并在 Tekton 的控制下将应用构建为容器镜像;
- Serving : 用户创建 Function 后,Function 生成相应的 Serving,用户无须手动创建。Serving CRD 创建后,函数将被部署到不同的运行时中,可以选择同步运行时或异步运行时。同步运行时可以通过 Knative Serving 或者 KEDA-HTTP (开发中)来支持,异步运行时通过 Dapr+KEDA 来支持。
- Events : 对于事件驱动型函数来说,需要提供事件管理的能力。由于 Knative Eventing 过于复杂,所以我们研发了一个新的事件管理框架叫 OpenFunction Events。
目前 OpenFunction 已经正式发布了 0.6.0 版本,与上一个版本相比,新增了许多值得关注的功能,包括函数插件、函数的分布式跟踪、控制自动缩放、HTTP 函数触发异步函数等。同时,异步运行时定义也被重构了。核心 API 也已经从 v1alpha1 升级到 v1beta1。值得一提的是,OpenFunction 团队还与 Apache SkyWalking 社区合作,增加了 FaaS 平台对函数可观测性的支持,现在大家可以直接在 SkyWalking UI 上通过图表来可视化 Serverless 函数的依赖关系并追踪函数的调用。
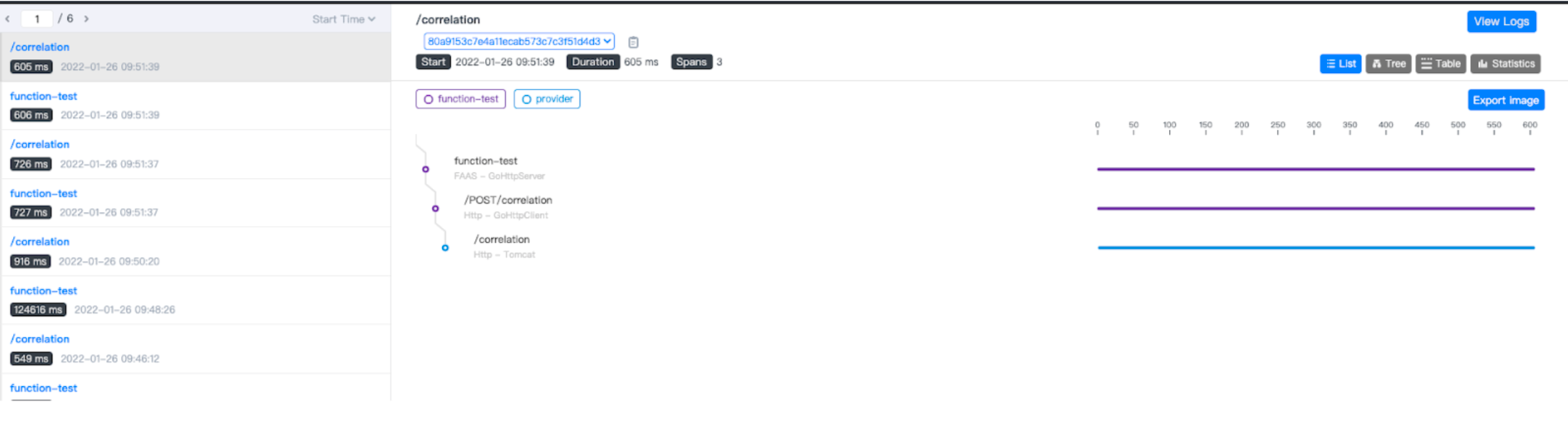
详情可参考这篇文章:OpenFunction 0.6.0 发布: FaaS 可观测性、HTTP 同步函数能力增强及更多特性。
关于 OpenFunction 的实际使用案例可以参考下面两篇文章:
社区生态
OpenFunction 自 2020 年 12 月开源并提交了第一个 commit,到 2021 年 5 月发布第一个 Release,仅一年多的时间就发布了 6 个大版本,吸引了 24 个 Contributors 和 480+ GitHub Stars,并且已经被驭势科技、中国联通、全象低代码平台等多个企业、组织和平台采用。截止目前参与贡献的企业和组织有:KubeSphere、驭势科技、Apache SkyWalking、SAP、中国联通、全象云,在此感谢每一位参与贡献的社区小伙伴对 OpenFunction 的支持和帮助,同时也欢迎更多的开发者和用户参与体验和贡献 OpenFunction。
除此之外,OpenFunction 团队还受邀参加了一些上游社区的例会并向大家介绍过 OpenFunction 项目及其典型用例,包括 CNCF 的 TAG-runtime 会议和 Dapr 社区会议。尤其 Dapr 社区对 OpenFunction 青睐有加,Dapr 联合创始人非常看好项目的发展前景,感兴趣的同学可以观看视频进一步了解。OpenFunction 社区也正在和 Dapr 社区及 Quarkus 社区合作以实现将 Java 代码编译为 Native 程序在 Quarkus 环境中运行,可大幅降低 Java 程序的资源占用并极大地提升性能。接下来,OpenFunction 项目发起人霍秉杰还将在 5 月 10 日举办的 Apache SkyWalking 峰会介绍其与 Apache SkyWalking 在函数可观测性领域的联合方案。
未来规划
得益于 CNCF 为项目提供了开源和中立的背书,OpenFunction 也将真正变成一个由 100% 社区驱动的开源项目。接下来,OpenFunction 将开发与实现如下功能,欢迎给社区提交需求与反馈:
- 支持更多语言的异步函数框架包括 Nodejs, Python, Java 和 .NET;
- 支持将 Java 函数编译成 Native 程序运行在 Quarkus 环境中;
- 使用 KEDA 的 http-add-on 作为 Knative Serving 之外同步函数运行时的又一个选择;
- 支持 OpenTelemetry 生态作为 SkyWalking 之外的另一个函数 Tracing 的方案;
- 增加 OpenFunction 控制台;
- 实现 Serverless 工作流;
- 对在边缘运行的函数有更好的支持;
- 预研基于 Pool 的冷启动优化方案;
- 使用 WebAssembly 作为更加轻量的运行时,结合 Rust 函数来加速冷启动速度。
持续开源开放
未来 KubeSphere 团队将继续保持开源、开放的理念,持续作为 OpenFunction 项目的参与方之一,推动国内和国际开源组织的生态建设,将 OpenFunction 社区培育成一个开放中立的开源社区与生态,与更多的函数计算平台及上下游生态伙伴进行深度合作,欢迎大家关注、使用 OpenFunction 以及参与社区贡献。
- ⚙️ GitHub:https://github.com/openfunction/openfunction
- 🔗 官网:https://openfunction.dev/
- 🙋 社群:微信搜索 kubesphere 加好友即可邀请您进群(或扫描下方二维码)

最后附上 OpenFunction 项目重磅参与者与关注者对 OpenFunction 的寄语:
吴晟
Apache SkyWalking 创始人
我很高兴和兴奋看到 OpenFunction 顺利加入 CNCF,作为一个仅一年多的年轻项目,这是一个项目从原型走向稳定,多元和成熟过程中的重要里程碑。作为 Apache SkyWalking 的一员,我有幸参加了 SkyWalking v9 迭代过程中与 OpenFunction 的集成。开放,平等,中立的开源合作模式,让人印象深刻。我们双方会在 Serverless 的可观测性上,进行紧密深入的合作,包括更多语言集成,日志的集成,平台的性能集成等等。祝贺 OpenFunction 成功加入沙箱孵化,期待项目更上一层楼。Enjoy your CNCF journey.
张海立
驭势科技云平台研发总监
驭势科技 UISEE 是中国领先的自动驾驶公司,OpenFunction 帮助我们找到了一种基于 FaaS / Serverless 的业务服务快速定制方案,我们已将它用于解决跨公私有云的、针对不同存储中间件的数据处理和落盘问题(参见 此案例)。期待有更多社区伙伴参与到 OpenFunction 的功能建设中,一起探索更多应用场景,提升研发效能!
张善友
深圳市友浩达科技有限公司CTO
OpenFunction 加入 CNCF 对我来说是一个额外的惊喜。我是最近一个月才成为 OpenFunction 的贡献者,我在最近 2 年实践 Dapr 的项目实战经验,让我深信基于 Dapr 的 OpenFunction 是一个非常有前景的 FaaS 项目。我现在负责建设 OpenFunction 的 .NET 支持框架开发工作,期待有更多的社区伙伴参与到 OpenFunction 的功能建设。
蔡礼泽
SAP, OpenFunction 早期用户
我从去年关注到OpenFunction,当时被它的技术选型所吸引,非常的前沿,让我想到了许多的可能性。之后一直关注着项目的技术走向还有社区发展,还有参与贡献。一个优秀的项目离不开社区的支持,OpenFunction的维护者非常专业与热情。优秀的技术设计加上专业的社区,我相信OpenFunction会在云原生领域大放异彩。
云原生 FaaS 平台 OpenFunction 入门教程
OpenFunction 0.6.0 上周已经正式发布了,带来了许多值得注意的功能,包括函数插件、函数的分布式跟踪、控制自动缩放、HTTP 函数触发异步函数等。同时,异步运行时定义也被重构了。核心 API 也已经从 v1alpha1 升级到 v1beta1。
官宣链接🔗:https://openfunction.dev/blog/2022/03/25/announcing-openfunction-0.6.0-faas-observability-http-trigger-and-more/
近年来,随着无服务器计算的兴起,出现了很多非常优秀的 Serverless 开源项目,其中比较杰出的有 Knative 和 OpenFaaS。但 Knative Serving 仅仅能运行应用,还不能运行函数,而 Serverless 的核心是函数计算,也就是 FaaS,因此比较遗憾;OpenFaaS 虽然很早就出圈了,但技术栈过于老旧,不能满足现代化函数计算平台的需求。
OpenFunction 便是这样一个现代化的云原生 FaaS(函数即服务)框架,它引入了很多非常优秀的开源技术栈,包括 Knative、Tekton、Shipwright、Dapr、KEDA 等,这些技术栈为打造新一代开源函数计算平台提供了无限可能:
- Shipwright 可以在函数构建的过程中让用户自由选择和切换镜像构建的工具,并对其进行抽象,提供了统一的 API;
- Knative 提供了优秀的同步函数运行时,具有强大的自动伸缩能力;
- KEDA 可以基于更多类型的指标来自动伸缩,更加灵活;
- Dapr 可以将不同应用的通用能力进行抽象,减轻开发分布式应用的工作量。
本文不打算讲一些非常高深的理论,作为刚跨进 Serverless 门槛的用户,更需要的是如何快速上手,以便对函数计算有一个感性的认知,在后续使用的过程中,咱们再慢慢理解其中的架构和设计。
本文将会带领大家快速部署和上手 OpenFunction,并通过一个 demo 来体验同步函数是如何运作的。
OpenFunction CLI 介绍
OpenFunction 从 0.5 版本开始使用全新的命令行工具 ofn 来安装各个依赖组件,它的功能更加全面,支持一键部署、一键卸载以及 Demo 演示的功能。用户可以通过设置相应的参数自定义地选择安装各个组件,同时可以选择特定的版本,使安装更为灵活,安装进程也提供了实时展示,使得界面更为美观。它支持的组件和其依赖的 Kubernetes 版本如下:
| Components | Kubernetes 1.17 | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20+ |
|---|---|---|---|---|
| Knative Serving | 0.21.1 | 0.23.3 | 0.25.2 | 1.0.1 |
| Kourier | 0.21.0 | 0.23.0 | 0.25.0 | 1.0.1 |
| Serving Default Domain | 0.21.0 | 0.23.0 | 0.25.0 | 1.0.1 |
| Dapr | 1.5.1 | 1.5.1 | 1.5.1 | 1.5.1 |
| Keda | 2.4.0 | 2.4.0 | 2.4.0 | 2.4.0 |
| Shipwright | 0.6.1 | 0.6.1 | 0.6.1 | 0.6.1 |
| Tekton Pipelines | 0.23.0 | 0.26.0 | 0.29.0 | 0.30.0 |
| Cert Manager | 1.5.4 | 1.5.4 | 1.5.4 | 1.5.4 |
| Ingress Nginx | na | na | 1.1.0 | 1.1.0 |
ofn 的安装参数 `ofn install` 解决了 OpenFunction 和 Kubernetes 的兼容问题,会自动根据 Kubernetes 版本选择兼容组件进行安装,同时提供多种参数以供用户选择。
| 参数 | 功能 |
|---|---|
| –all | 用于安装 OpenFunction 及其所有依赖。 |
| –async | 用于安装 OpenFunction 的异步运行时(Dapr & Keda)。 |
| –cert-manager * | 用于安装 Cert Manager。 |
| –dapr * | 用于安装 Dapr。 |
| –dry-run | 用于提示当前命令所要安装的组件及其版本。 |
| –ingress * | 用于安装 Ingress Nginx。 |
| –keda * | 用于安装 Keda。 |
| –knative | 用于安装 Knative Serving(以Kourier为默认网关) |
| –region-cn | 针对访问 gcr.io 或 github.com 受限的用户。 |
| –shipwright * | 用于安装 ShipWright。 |
| –sync | 用于安装 OpenFunction Sync Runtime(待支持)。 |
| –upgrade | 在安装时将组件升级到目标版本。 |
| –verbose | 显示粗略信息。 |
| –version | 用于指定要安装的 OpenFunction 的版本。(默认为 “v0.6.0”) |
| –timeout | 设置超时时间。默认为5分钟。 |
使用 OpenFunction CLI 部署 OpenFunction
有了命令行工具 ofn 之后,OpenFunction 部署起来非常简单。首先需要安装 ofn,以 amd64 版本的 Linux 为例,仅需两步即可:
1、下载 ofn
$ wget -c https://github.com/OpenFunction/cli/releases/download/v0.5.1/ofn_linux_amd64.tar.gz -O - | tar -xz
2、为 ofn 赋予权限并移动到 /usr/local/bin/ 文件夹下。
$ chmod +x ofn && mv ofn /usr/local/bin/
安装好 ofn 之后,仅需一步即可完成 OpenFunction 的安装。虽然使用 --all 选项可以安装所有组件,但我知道大部分小伙伴的真实需求是不想再额外装一下 Ingress Controller 的,这个也好办,我们可以直接指定需要安装的组件,排除 ingress,命令如下:
$ ofn install --knative --async --shipwright --cert-manager --region-cn
Start installing OpenFunction and its dependencies.
The following components will be installed:
+------------------+---------+
| COMPONENT | VERSION |
+------------------+---------+
| OpenFunction | 0.6.0 |
| Keda | 2.4.0 |
| Dapr | 1.5.1 |
| Shipwright | 0.6.1 |
| CertManager | 1.5.4 |
| Kourier | 1.0.1 |
| DefaultDomain | 1.0.1 |
| Knative Serving | 1.0.1 |
| Tekton Pipelines | 0.30.0 |
+------------------+---------+
✓ Dapr - Completed!
✓ Keda - Completed!
✓ Knative Serving - Completed!
✓ Shipwright - Completed!
✓ Cert Manager - Completed!
✓ OpenFunction - Completed!
🚀 Completed in 2m47.901328069s.
██████╗ ██████╗ ███████╗███╗ ██╗
██╔═══██╗██╔══██╗██╔════╝████╗ ██║
██║ ██║██████╔╝█████╗ ██╔██╗ ██║
██║ ██║██╔═══╝ ██╔══╝ ██║╚██╗██║
╚██████╔╝██║ ███████╗██║ ╚████║
╚═════╝ ╚═╝ ╚══════╝╚═╝ ╚═══╝
███████╗██╗ ██╗███╗ ██╗ ██████╗████████╗██╗ ██████╗ ███╗ ██╗
██╔════╝██║ ██║████╗ ██║██╔════╝╚══██╔══╝██║██╔═══██╗████╗ ██║
█████╗ ██║ ██║██╔██╗ ██║██║ ██║ ██║██║ ██║██╔██╗ ██║
██╔══╝ ██║ ██║██║╚██╗██║██║ ██║ ██║██║ ██║██║╚██╗██║
██║ ╚██████╔╝██║ ╚████║╚██████╗ ██║ ██║╚██████╔╝██║ ╚████║
╚═╝ ╚═════╝ ╚═╝ ╚═══╝ ╚═════╝ ╚═╝ ╚═╝ ╚═════╝ ╚═╝ ╚═══╝
虽然本文演示的是同步函数,但这里把异步运行时也装上了,如果你不需要,可以把 --async 这个参数去掉,不影响本文的实验。
安装完成后,会创建这几个 namespace:
$ kubectl get ns
NAME STATUS AGE
cert-manager Active 17m
dapr-system Active 4m34s
io Active 3m31s
keda Active 4m49s
knative-serving Active 4m41s
kourier-system Active 3m57s
openfunction Active 3m37s
shipwright-build Active 4m26s
tekton-pipelines Active 4m50s
每个 namespace 对应上面安装的各个组件。目前 OpenFunction 的 Webhook 需要使用 CertManager 来验证 API 访问,后续我们会去掉这个依赖,不再需要安装 CertManager。
自定义域名后缀
Knative Serving 目前使用 Kourier 作为入口网关,由于我们没有部署 Ingress Controller,所以我们访问函数只有 Kourier 这一个入口。
Kourier 是一个基于 Envoy Proxy 的轻量级网关,是专门对于 Knative Serving 服务访问提供的一个网关实现。关于 Envoy 控制平面的细节本文不作赘述,感兴趣的可以去阅读 Kourier 官方文档和源码。这里我们只需要知道 Kourier 会为函数访问提供一个入口,这个访问入口是通过域名来提供的,我们要做的工作就是将相关域名解析到 Kourier 的 ClusterIP。
Kourier 默认创建了两个 Service:
$ kubectl -n kourier-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kourier LoadBalancer 10.233.7.202 <pending> 80:31655/TCP,443:30980/TCP 36m
kourier-internal ClusterIP 10.233.47.71 <none> 80/TCP 36m
只需要将与函数访问相关域名解析到 10.233.47.71 即可。
虽然每个函数的域名都是不同的,但域名后缀是一样的,可以通过泛域名解析来实现解析与函数相关的所有域名。Kourier 默认的域名后缀是 example.com,通过 Knative 的 ConfigMap config-domain 来配置:
$ kubectl -n knative-serving get cm config-domain -o yaml
apiVersion: v1
data:
_example: |
################################
# #
# EXAMPLE CONFIGURATION #
# #
################################
# This block is not actually functional configuration,
# but serves to illustrate the available configuration
# options and document them in a way that is accessible
# to users that `kubectl edit` this config map.
#
# These sample configuration options may be copied out of
# this example block and unindented to be in the data block
# to actually change the configuration.
# Default value for domain.
# Although it will match all routes, it is the least-specific rule so it
# will only be used if no other domain matches.
example.com: |
# These are example settings of domain.
# example.org will be used for routes having app=nonprofit.
example.org: |
selector:
app: nonprofit
# Routes having the cluster domain suffix (by default 'svc.cluster.local')
# will not be exposed through Ingress. You can define your own label
# selector to assign that domain suffix to your Route here, or you can set
# the label
# "networking.knative.dev/visibility=cluster-local"
# to achieve the same effect. This shows how to make routes having
# the label app=secret only exposed to the local cluster.
svc.cluster.local: |
selector:
app: secret
kind: ConfigMap
metadata:
annotations:
knative.dev/example-checksum: 81552d0b
labels:
app.kubernetes.io/part-of: knative-serving
app.kubernetes.io/version: 1.0.1
serving.knative.dev/release: v1.0.1
name: config-domain
namespace: knative-serving
将其中的 _example 对象删除,添加一个默认域名(例如 openfunction.dev),最终修改结果如下:
$ kubectl -n knative-serving get cm config-domain -o yaml
apiVersion: v1
data:
openfunction.dev: ""
kind: ConfigMap
metadata:
annotations:
knative.dev/example-checksum: 81552d0b
labels:
app.kubernetes.io/part-of: knative-serving
app.kubernetes.io/version: 1.0.1
serving.knative.dev/release: v1.0.1
name: config-domain
namespace: knative-serving
配置集群域名解析
为了便于在 Kubernetes 的 Pod 中访问函数,可以对 Kubernetes 集群的 CoreDNS 进行改造,使其能够对域名后缀 openfunction.dev 进行泛解析,需要在 CoreDNS 的配置中添加一段内容:
template IN A openfunction.dev {
match .*\.openfunction\.dev
answer "{{ .Name }} 60 IN A 10.233.47.71"
fallthrough
}
修改完成后的 CoreDNS 配置如下:
$ kubectl -n kube-system get cm coredns -o yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
ready
template IN A openfunction.dev {
match .*\.openfunction\.dev
answer "{{ .Name }} 60 IN A 10.233.47.71"
fallthrough
}
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
hosts /etc/coredns/NodeHosts {
ttl 60
reload 15s
fallthrough
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
...
同步函数 demo 示例
配置完域名解析后,接下来可以运行一个同步函数的示例来验证一下。OpenFunction 官方仓库提供了多种语言的同步函数示例:
这里我们选择 Go 语言的函数示例,先来看一下最核心的部署清单:
# function-sample.yaml
apiVersion: core.openfunction.io/v1beta1
kind: Function
metadata:
name: function-sample
spec:
version: "v2.0.0"
image: "openfunctiondev/sample-go-func:latest"
imageCredentials:
name: push-secret
port: 8080 # default to 8080
build:
builder: openfunction/builder-go:latest
env:
FUNC_NAME: "HelloWorld"
FUNC_CLEAR_SOURCE: "true"
srcRepo:
url: "https://github.com/OpenFunction/samples.git"
sourceSubPath: "functions/knative/hello-world-go"
revision: "main"
serving:
template:
containers:
- name: function
imagePullPolicy: Always
runtime: "knative"
Function 是由 CRD 定义的一个 CR,用来将函数转换为最终运行的应用。这个例子里面包含了两个组件:
- build : 通过 Shipwright 选择不同的镜像构建工具,最终将应用构建为容器镜像;
- Serving : 通过 Serving CRD 将应用部署到不同的运行时中,可以选择同步运行时或异步运行时。这里选择的是同步运行时 knative。
国内环境由于不可抗因素,可以通过 GOPROXY 从公共代理镜像中快速拉取所需的依赖代码,只需在部署清单中的 build 阶段添加一个环境变量 FUNC_GOPROXY 即可:
# function-sample.yaml
apiVersion: core.openfunction.io/v1beta1
kind: Function
metadata:
name: function-sample
spec:
version: "v2.0.0"
image: "openfunctiondev/sample-go-func:latest"
imageCredentials:
name: push-secret
port: 8080 # default to 8080
build:
builder: openfunction/builder-go:latest
env:
FUNC_NAME: "HelloWorld"
FUNC_CLEAR_SOURCE: "true"
FUNC_GOPROXY: "https://proxy.golang.com.cn,direct"
srcRepo:
url: "https://github.com/OpenFunction/samples.git"
sourceSubPath: "functions/knative/hello-world-go"
revision: "main"
serving:
template:
containers:
- name: function
imagePullPolicy: Always
runtime: "knative"
在创建函数之前,需要先创建一个 secret 来存储 Docker Hub 的用户名和密码:
$ REGISTRY_SERVER=https://index.docker.io/v1/ REGISTRY_USER=<your_registry_user> REGISTRY_PASSWORD=<your_registry_password>
$ kubectl create secret docker-registry push-secret \
--docker-server=$REGISTRY_SERVER \
--docker-username=$REGISTRY_USER \
--docker-password=$REGISTRY_PASSWORD
下面通过 kubectl 创建这个 Function:
$ kubectl apply -f function-sample.yaml
查看 Function 运行状况:
$ kubectl get function
NAME BUILDSTATE SERVINGSTATE BUILDER SERVING URL AGE
function-sample Building builder-6ht76 5s
目前正处于 Build 阶段,builder 的名称是 builder-6ht76。查看 builder 的运行状态:
$ kubectl get builder
NAME PHASE STATE REASON AGE
builder-6ht76 Build Building 50s
这个 builder 会启动一个 Pod 来构建镜像:
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
builder-6ht76-buildrun-jvtwk-vjlgt-pod 2/4 NotReady 0 2m11s
这个 Pod 中包含了 4 个容器:
step-source-default : 拉取源代码;
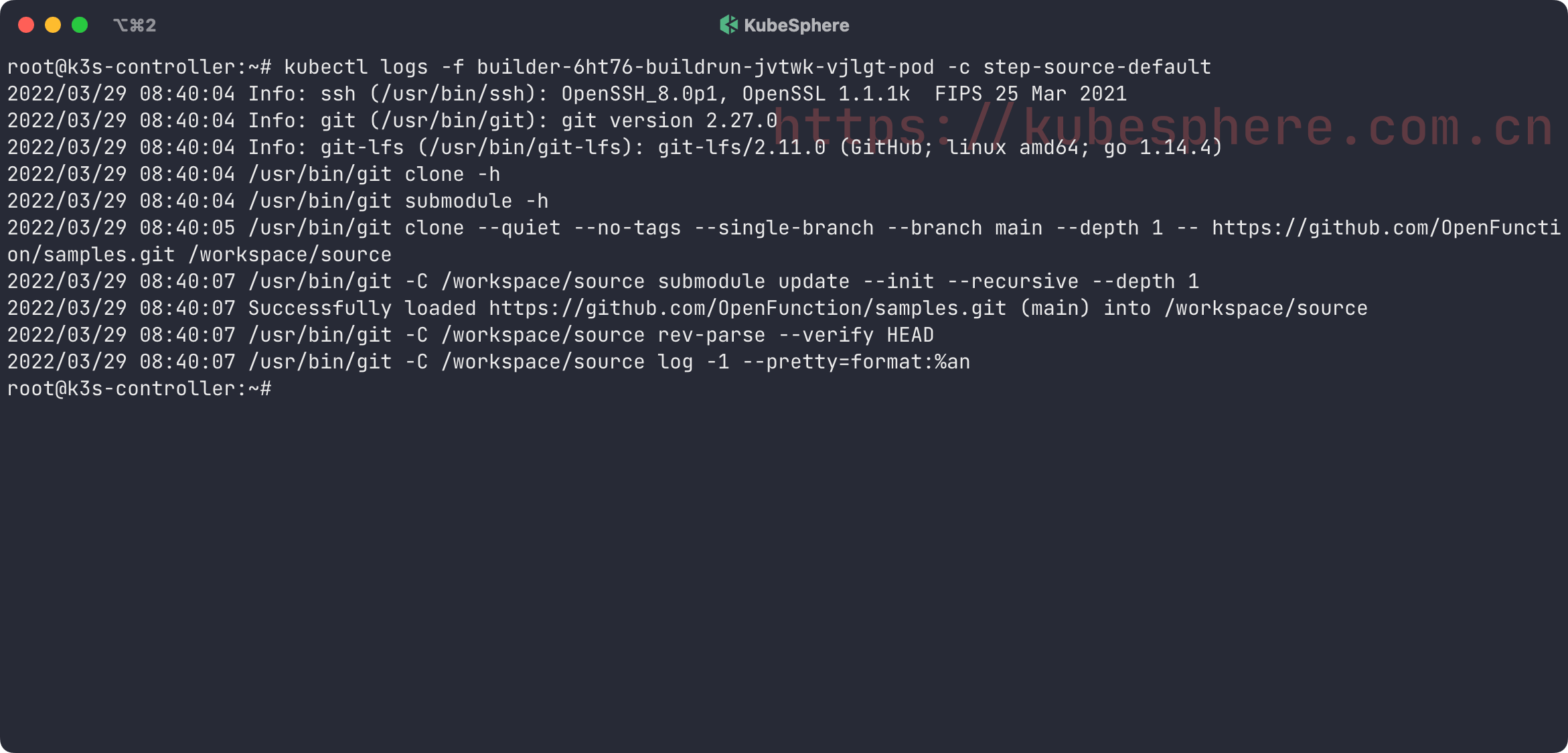
step-prepare : 设置环境变量;
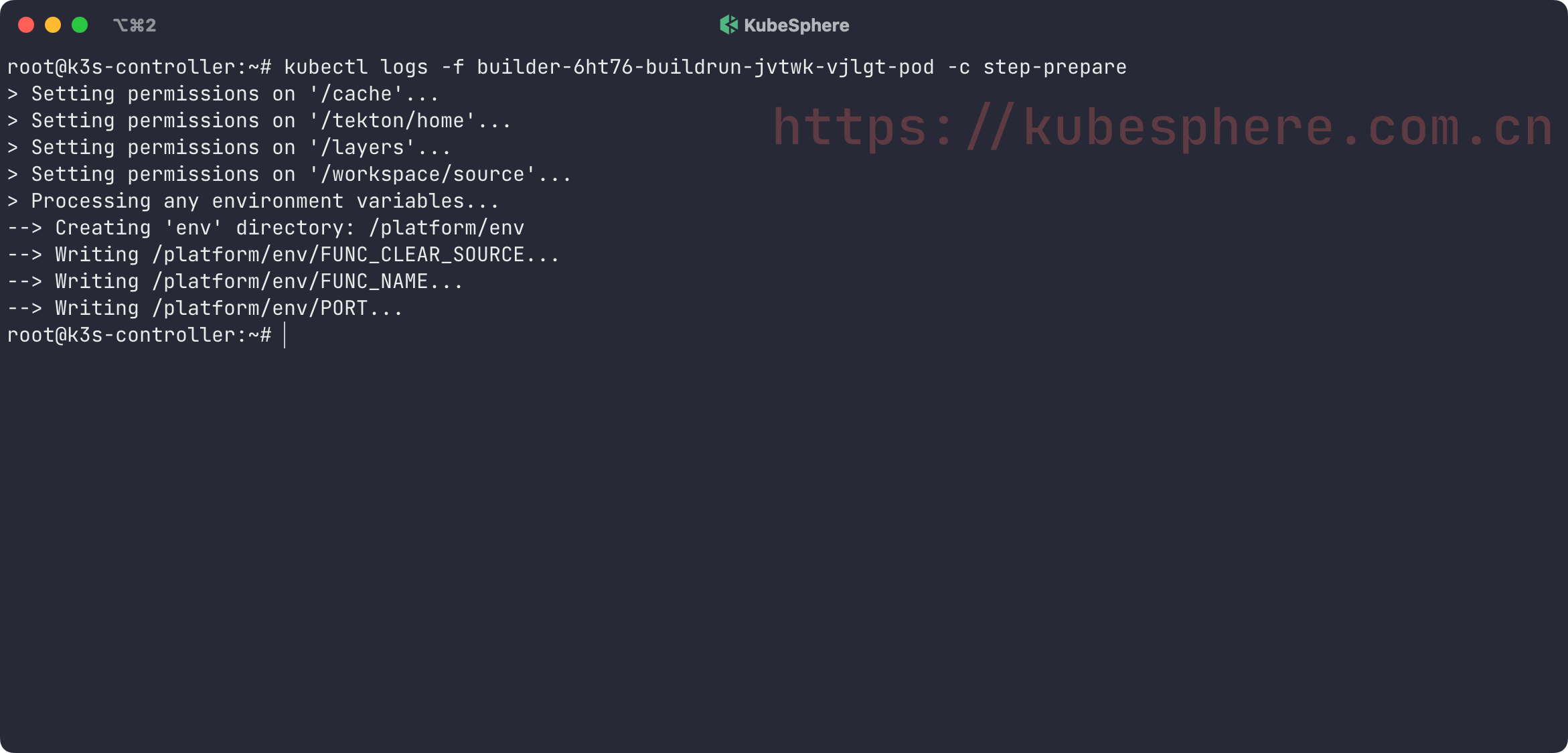
step-create : 构建镜像;

step-results : 输出镜像的 digest。
再次查看函数状态:
$ kubectl get function
NAME BUILDSTATE SERVINGSTATE BUILDER SERVING URL AGE
function-sample Succeeded Running builder-6ht76 serving-6w4rn https://openfunction.io/default/function-sample 6m
已经由之前的 Building 状态变成了 Runing 状态。
这里的 URL 我们无法直接访问,因为没有部署 Ingress Controller。不过我们可以通过其他方式来访问,Kourier 把每个访问入口抽象为一个 CR 叫 ksvc,每一个 ksvc 对应一个函数的访问入口,可以看下目前有没有创建 ksvc:
$ kubectl get ksvc
NAME URL LATESTCREATED LATESTREADY READY REASON
serving-6w4rn-ksvc-k4x29 http://serving-6w4rn-ksvc-k4x29.default.openfunction.dev serving-6w4rn-ksvc-k4x29-v200 serving-6w4rn-ksvc-k4x29-v200 True
函数的访问入口就是 http://serving-6w4rn-ksvc-k4x29.default.openfunction.dev。由于在前面的章节中已经配置好了域名解析,这里可以启动一个 Pod 来直接访问该域名:
$ kubectl run curl --image=radial/busyboxplus:curl -i --tty
If you don't see a command prompt, try pressing enter.
[ root@curl:/ ]$
[ root@curl:/ ]$ curl http://serving-6w4rn-ksvc-k4x29.default.openfunction.dev/default/function-sample/World
Hello, default/function-sample/World!
[ root@curl:/ ]$ curl http://serving-6w4rn-ksvc-k4x29.default.openfunction.dev/default/function-sample/OpenFunction
Hello, default/function-sample/OpenFunction!
访问这个函数时会自动触发运行一个 Pod:
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
serving-6w4rn-ksvc-k4x29-v200-deployment-688d58bfb-6fvcg 2/2 Running 0 7s
这个 Pod 使用的镜像就是之前 build 阶段构建的镜像。事实上这个 Pod 是由 Deployment 控制的,在没有流量时,这个 Deployment 的副本数是 0。当有新的流量进入时,会先进入 Knative 的 Activator,Activator 接收到流量后会通知 Autoscaler(自动伸缩控制器),然后 Autoscaler 将 Deployment 的副本数扩展到 1,最后 Activator 会将流量转发到实际的 Pod 中,从而实现服务调用。这个过程也叫冷启动。
如果你不再访问这个入口,过一段时间之后,Deployment 的副本数就会被收缩为 0:
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
serving-6w4rn-ksvc-k4x29-v200-deployment 0/0 0 0 22m
总结
通过本文的示例,相信大家应该能够体会到一些函数计算的优势,它为我们带来了我们所期望的对业务场景快速拆解重构的能力。作为用户,只需要专注于他们的开发意图,编写函数代码,并上传到代码仓库,其他的东西不需要关心,不需要了解基础设施,甚至不需要知道容器和 Kubernetes 的存在。函数计算平台会自动为您分配好计算资源,并弹性地运行任务,只有当您需要访问的时候,才会通过扩容来运行任务,其他时间并不会消耗计算资源。
Cloud Native Buildpacks 入门教程
作者:米开朗基杨,方阗
云原生正在吞并软件世界,容器改变了传统的应用开发模式,如今研发人员不仅要构建应用,还要使用 Dockerfile 来完成应用的容器化,将应用及其依赖关系打包,从而获得更可靠的产品,提高研发效率。
随着项目的迭代,达到一定的规模后,就需要运维团队和研发团队之间相互协作。运维团队的视角与研发团队不同,他们对镜像的需求是安全和标准化。比如:
- 不同的应用应该选择哪种基础镜像?
- 应用的依赖有哪些版本?
- 应用需要暴露的端口有哪些?
为了优化运维效率,提高应用安全性,研发人员需要不断更新 Dockerfile 来实现上述目标。同时运维团队也会干预镜像的构建,如果基础镜像中有 CVE 被修复了,运维团队就需要更新 Dockerfile,使用较新版本的基础镜像。总之,运维与研发都需要干预 Dockerfile,无法实现解耦。
为了解决这一系列的问题,涌现出了更加优秀的产品来构建镜像,其中就包括 Cloud Native Buildpacks (СNB)。CNB 基于模块化提供了一种更加快速、安全、可靠的方式来构建符合 OCI 规范的镜像,实现了研发与运维团队之间的解耦。
在介绍 CNB 之前,我们先来阐述几个基本概念。
符合 OCI 规范的镜像
如今,容器运行时早就不是 Docker 一家独大了。为了确保所有的容器运行时都能运行任何构建工具生成的镜像,Linux 基金会与 Google,华为,惠普,IBM,Docker,Red Hat,VMware 等公司共同宣布成立开放容器项目(OCP),后更名为开放容器倡议(OCI)。OCI 定义了围绕容器镜像格式和运行时的行业标准,给定一个 OCI 镜像,任何实现 OCI 运行时标准的容器运行时都可以使用该镜像运行容器。
如果你要问 Docker 镜像与 OCI 镜像之间有什么区别,如今的答案是:几乎没有区别。有一部分旧的 Docker 镜像在 OCI 规范之前就已经存在了,它们被成为 Docker v1 规范,与 Docker v2 规范是不兼容的。而 Docker v2 规范捐给了 OCI,构成了 OCI 规范的基础。如今所有的容器镜像仓库、Kubernetes 平台和容器运行时都是围绕 OCI 规范建立的。
什么是 Buildpacks
Buildpacks 项目最早由 Heroku 在 2011 年发起, 被以 Cloud Foundry 为代表的 PaaS 平台广泛采用。
一个 buildpack 指的就是一个将源代码变成 PaaS 平台可运行的压缩包的程序,通常情况下,每个 buildpack 封装了单一的语言生态系统的工具链,例如 Ruby、Go、NodeJs、Java、Python 等都有专门的 buildpack。
你可以将 buildpack 理解成一坨脚本,这坨脚本的作用是将应用的可执行文件及其依赖的环境、配置、启动脚本等打包,然后上传到 Git 等仓库中,打好的压缩包被称为 droplet。
然后 Cloud Foundry 会通过调度器选择一个可以运行这个应用的虚拟机,然后通知这个机器上的 Agent 下载应用压缩包,按照 buildpack 指定的启动命令,启动应用。
到了 2018 年 1 月,Pivotal 和 Heroku 联合发起了 Cloud Native Buildpacks(CNB) 项目,并在同年 10 月让这个项目进入了 CNCF。
2020 年 11 月,CNCF 技术监督委员会(TOC)投票决定将 CNB 从沙箱项目晋升为孵化项目。是时候好好研究一下 CNB 了。
为什么需要 Cloud Native Buildpacks
Cloud Native Buildpacks(CNB) 可以看成是基于云原生的 Buildpacks 技术,它支持现代语言生态系统,对开发者屏蔽了应用构建、部署的细节,如选用哪种操作系统、编写适应镜像操作系统的处理脚本、优化镜像大小等等,并且会产出 OCI 容器镜像,可以运行在任何兼容 OCI 镜像标准的集群中。CNB 还拥抱了很多更加云原生的特性,例如跨镜像仓库的 blob 挂载和镜像层级 rebasing。
由此可见 CNB 的镜像构建方式更加标准化、自动化,与 Dockerfile 相比,Buildpacks 为构建应用提供了更高层次的抽象,Buildpacks 对 OCI 镜像构建的抽象,就类似于 Helm 对 Deployment 编排的抽象。
2020 年 10 月,Google Cloud 开始宣布全面支持 Buildpacks,包含 Cloud Run、Anthos 和 Google Kubernetes Engine (GKE)。目前 IBM Cloud、Heroku 和 Pivital 等公司皆已采用 Buildpacks,如果不出意外,其他云供应商很快就会效仿。
Buildpacks 的优点:
- 针对同一构建目的的应用,不用重复编写构建文件(只需要使用一个 Builder)。
- 不依赖 Dockerfile。
- 可以根据丰富的元数据信息(buildpack.toml)轻松地检查到每一层(buildpacks)的工作内容。
- 在更换了底层操作系统之后,不需要重新改写镜像构建过程。
- 保证应用构建的安全性和合规性,而无需开发者干预。

Buildpacks 社区还给出了一个表格来对比同类应用打包工具:

可以看到 Buildpacks 与其他打包工具相比,支持的功能更多,包括:缓存、源代码检测、插件化、支持 rebase、重用、CI/CD 多种生态。
Cloud Native Buildpacks 工作原理
Cloud Native Buildpacks 主要由 3 个组件组成: Builder、Buildpack 和 Stack。
Buildpack
Buildpack 本质是一个可执行单元的集合,一般包括检查程序源代码、构建代码、生成镜像等。一个典型的 Buildpack 需要包含以下三个文件:
- buildpack.toml – 提供 buildpack 的元数据信息。
- bin/detect – 检测是否应该执行这个 buildpack。
- bin/build – 执行 buildpack 的构建逻辑,最终生成镜像。
Builder
Buildpacks 会通过“检测”、“构建”、“输出”三个动作完成一个构建逻辑。通常为了完成一个应用的构建,我们会使用到多个 Buildpacks,那么 Builder 就是一个构建逻辑的集合,包含了构建所需要的所有组件和运行环境的镜像。
我们通过一个假设的流水线来尝试理解 Builder 的工作原理:
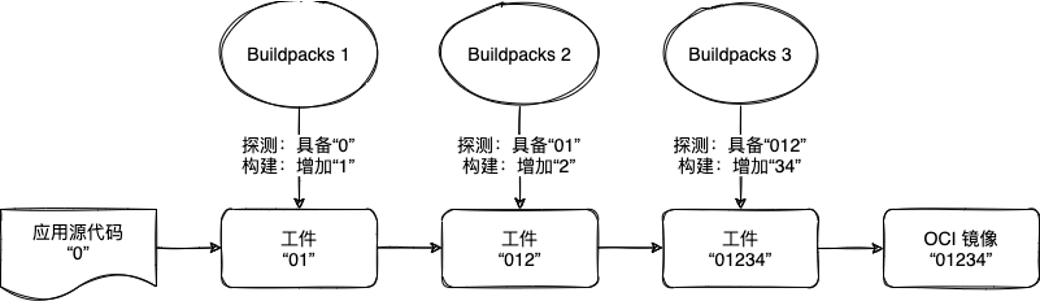
- 最初,我们作为应用的开发者,准备了一份应用源代码,这里我们将其标识为 “0”。
- 然后应用 “0” 来到了第一道工序,我们使用 Buildpacks1 对其进行加工。在这个工序中,Buildpacks1 会检查应用是否具有 “0” 标识,如果有,则进入构建过程,即为应用标识添加 “1”,使应用标识变更为 “01”。
- 同理,第二道、第三道工序也会根据自身的准入条件判断是否需要执行各自的构建逻辑。
在这个例子中,应用满足了三道工序的准入条件,所以最终输出的 OCI 镜像的内容为 “01234” 的标识。
对应到 Buildpacks 的概念中,Builders 就是 Buildpacks 的有序组合,包含一个基础镜像叫 build image、一个 lifecycle 和对另一个基础镜像 run image 的应用。Builders 负责将应用源代码构建成应用镜像(app image)。
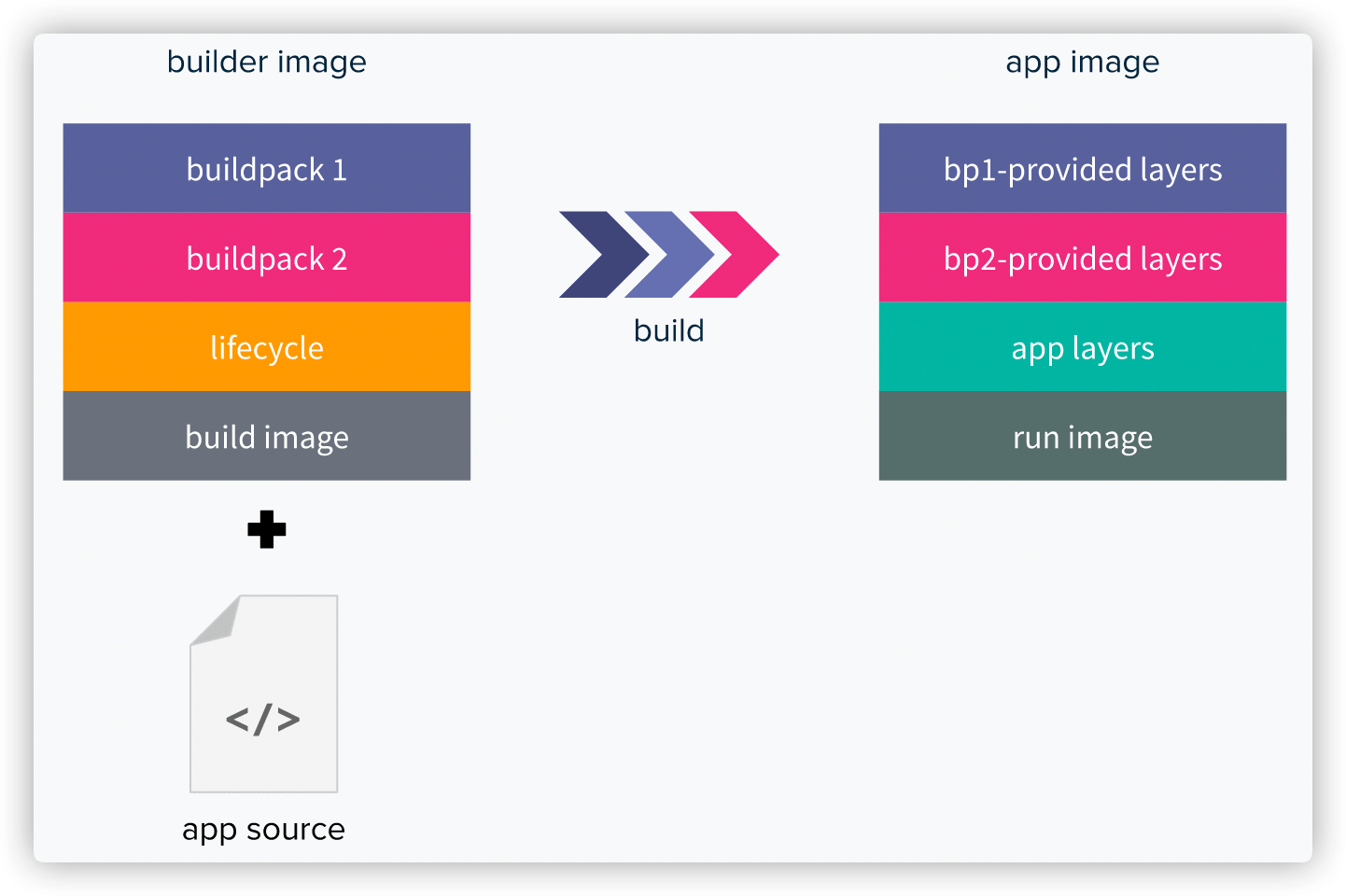
build image 为 Builders 提供基础环境(例如 带有构建工具的 Ubuntu Bionic OS 镜像),而 run image 在运行时为应用镜像(app image)提供基础环境。build image 和 run image 的组合被称为 Stack。
Stack
上面提到,build image 和 run image 的组合被称为 Stack,也就是说,它定义了 Buildpacks 的执行环境和最终应用的基础镜像。
你可以将 build image 理解为 Dockerfile 多阶段构建中第一阶段的 base 镜像,将 run image 理解为第二阶段的 base 镜像。
上述 3 个组件都是以 Docker 镜像的形式存在,并且提供了非常灵活的配置选项,还拥有控制所生成镜像的每一个 layer 的能力。结合其强大的 caching 和 rebasing 能力,定制的组件镜像可以被多个应用重复利用,并且每一个 layer 都可以根据需要单独更新。
Lifecycle 是 Builder 中最重要的概念,它将由应用源代码到镜像的构建步骤抽象出来,完成了对整个过程的编排,并最终产出应用镜像。下面我们单独用一个章节来介绍 Lifecycle。
构建生命周期(Lifecyle)
Lifecycle 将所有 Buildpacks 的探测、构建过程抽离出来,分成两个大的步骤聚合执行:Detect 和 Build。这样一来就降低了 Lifecycle 的架构复杂度,便于实现自定义的 Builder。
除了 Detect 和 Build 这两个主要步骤,Lifecycle 还包含了一些额外的步骤,我们一起来解读。
Detect
我们之前提到,在 Buildpack 中包含了一个用于探测的 /bin/detect 文件,那么在 Detect 过程中,Lifecycle 会指导所有 Buildpacks 中的 /bin/detect 按顺序执行,并从中获取执行结果。
那么 Lifecycle 把 Detect 和 Build 分开后,又是怎么维系这两个过程中的关联关系呢?
Buildpacks 在 Detect 和 Build 阶段,通常都会告知在自己这个过程中会需要哪些前提,以及自己会提供哪些结果。
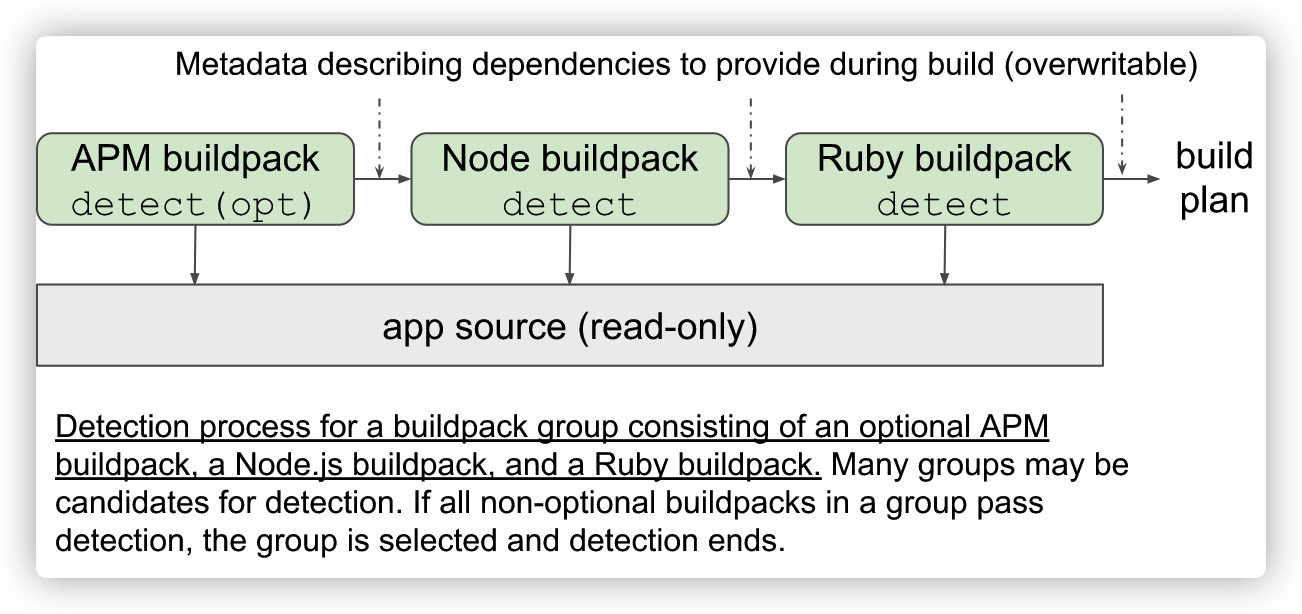
在 Lifecycle 中,提供了一个叫做 Build Plan 的结构体用于存放每个 Buildpack 的所需物和产出物。
type BuildPlanEntry struct {
Providers `toml:“providers”`
Requires `toml:"requires"`
同时,Lifecycle 也规定,只有当所有产出物都匹配有一个对应的所需物时,这些 Buildpacks 才能组合成一个 Builder。
Analysis
Buildpacks 在运行中会创建一些目录,在 Lifecycle 中这些目录被称为 layer。那么为了这些 layer 中,有一些是可以作为缓存提供给下一个 Buildpacks 使用的,有一些则是需要在应用运行时起作用的,还有的则是需要被清理掉。怎么才能更灵活地控制这些 layer ?
Lifecycle 提供了三个开关参数,用于表示每一个 layer 期望的处理方式:
- launch 表示这个 layer 是否将在应用运行时起作用。
- build 表示这个 layer 是否将在后续的构建过程中被访问。
- cache 则表示这个 layer 是否将作为缓存。
之后,Lifecycle 再根据一个关系矩阵来判断 layer 的最终归宿。我们也可以简单的理解为,Analysis 阶段为构建、应用运行提供了缓存。
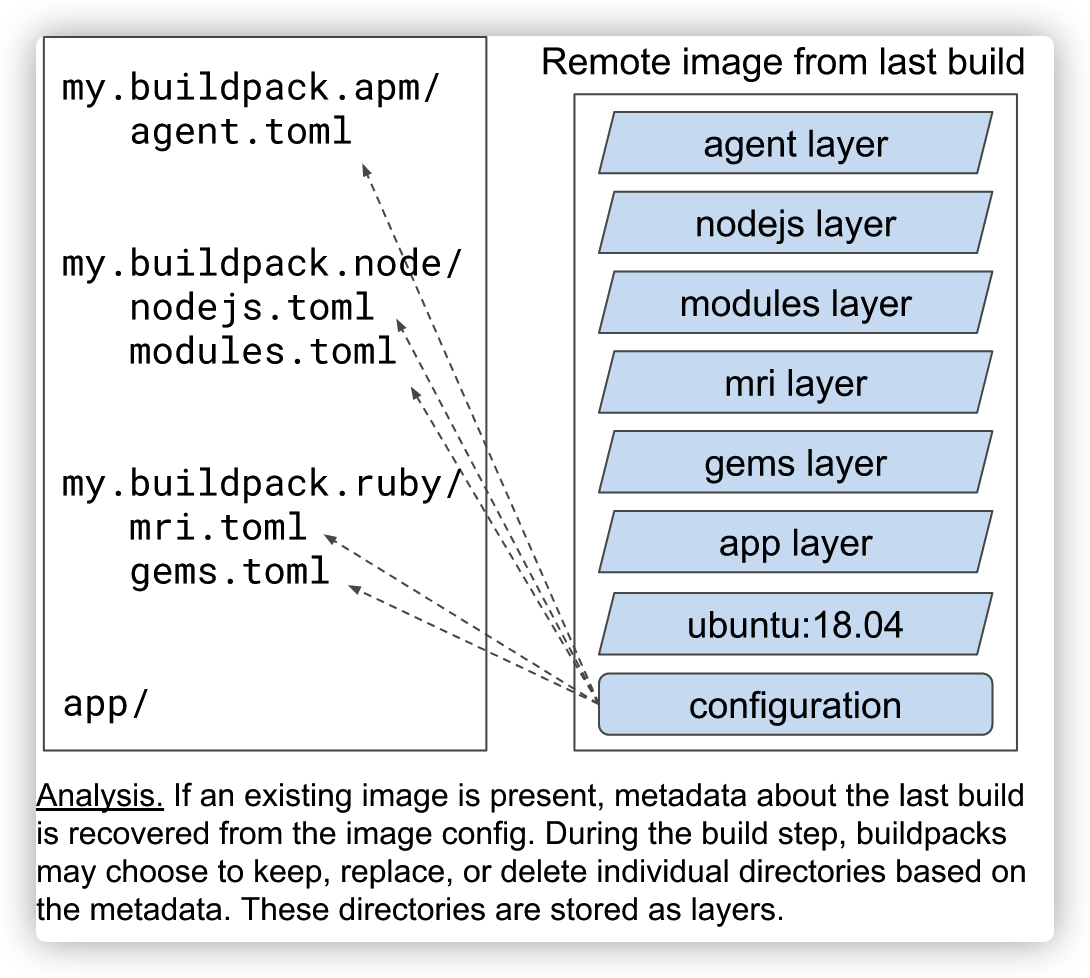
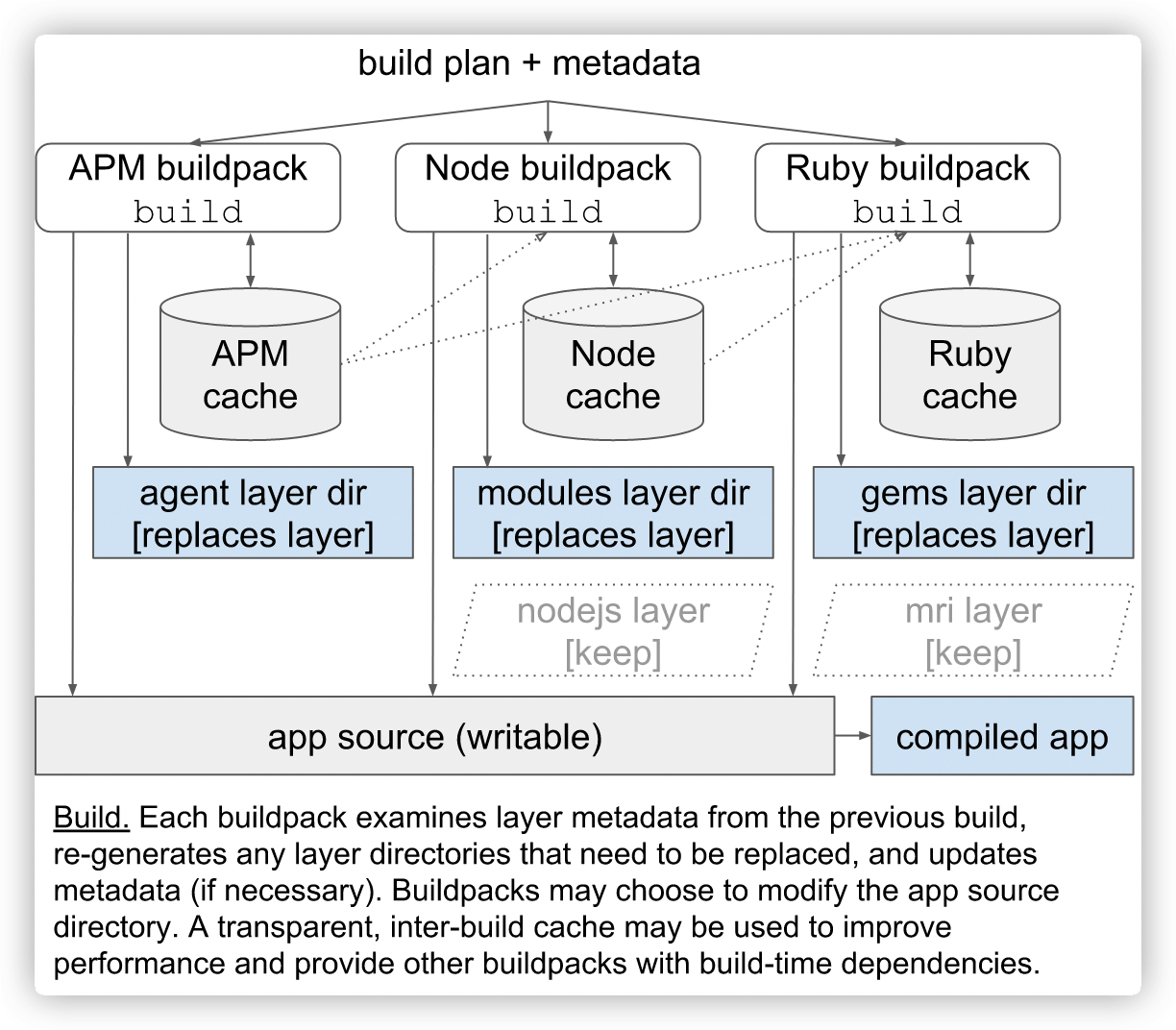
Build
Build 阶段会利用 Detect 阶段产出的 build plan,以及环境中的元数据信息,配合保留至本阶段的 layers,对应用源码执行 Buildpacks 中的构建逻辑。最终生成可运行的应用工件。
Export
Export 阶段比较好理解,在完成了上述构建之后,我们需要将最后的构建结果产出为一个 OCI 标准镜像,这样一来,这个 App 工件就可以运行在任何兼容 OCI 标准的集群中。
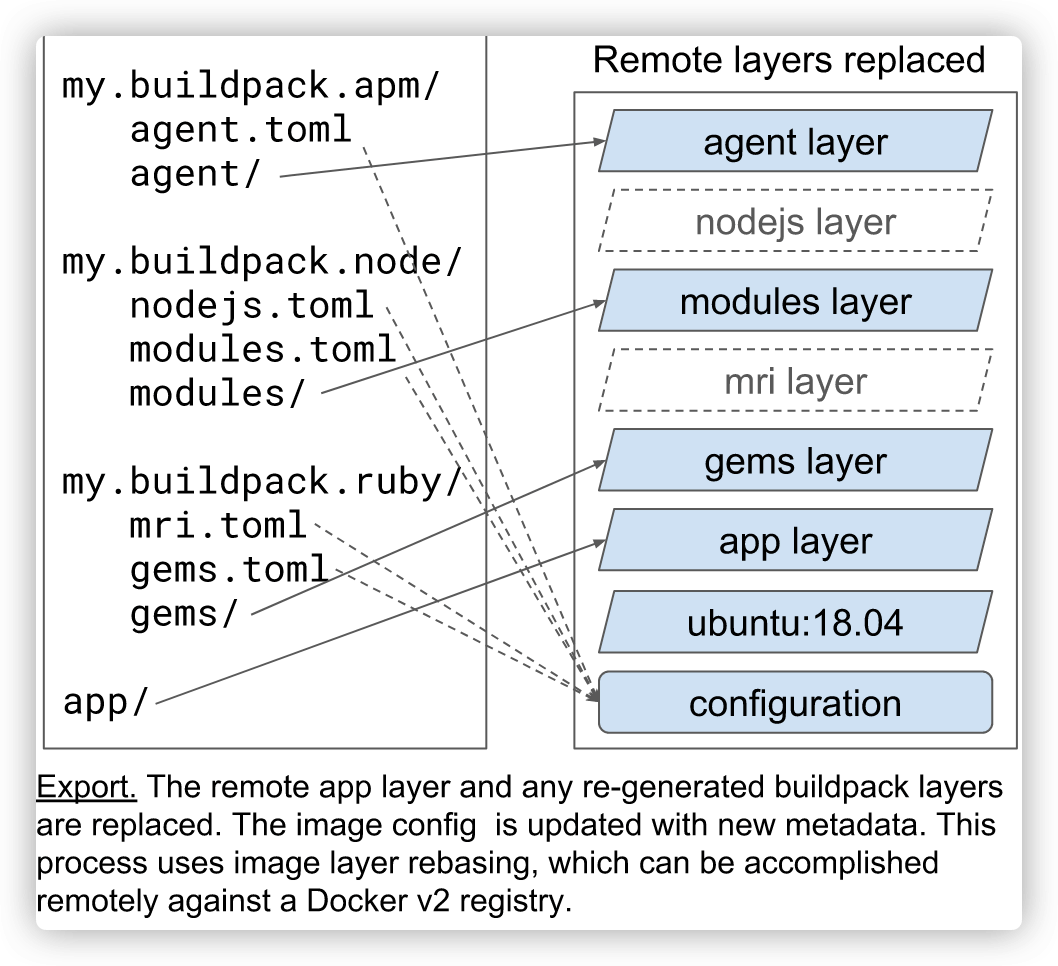
Rebase
在 CNB 的设计中,最后 app 工件实际是运行在 stack 的 run image 之上的。可以理解为 run image 以上的工件是一个整体,它与 run image 以 ABI(application binary interface) 的形式对接,这就使得这个工件可以灵活切换到另一个 run image 上。
这个动作其实也是 Lifecycle 的一部分,叫做 rebase。在构建镜像的过程中也有一次 rebase,发生在 app 工件由 build image 切换到 run image 上。

这种机制也是 CNB 对比 Dockerfile 最具优势的地方。比如在一个大型的生产环境中,如果容器镜像的 OS 层出现问题,需要更换镜像的 OS 层,那么针对不同类型的应用镜像就需要重写他们的 dockerfile 并验证新的 dockerfile 是否可行,以及新增加的层与已存在的层之间是否有冲突,等等。而使用 CNB 只需要做一次 rebase 即可,简化了大规模生产中镜像的升级工作。
以上就是关于 CNB 构建镜像的流程分析,总结来说:
- Buildpacks 是最小构建单元,执行具体的构建操作;
- Lifecycle 是 CNB 提供的镜像构建生命周期接口;
- Builder 是若干 Buildpacks 加上 Lifecycle 以及 stack 形成的具备特定构建目的的构建器。

再精减一下:
- build image + run image = stack
- stack(build image) + buildpacks + lifecycle = builder
- stack(run image) + app artifacts = app
那么现在问题来了,这个工具怎么使用呢?
Platform
这时候就需要一个 Platform,Platform 其实是 Lifecycle 的执行者。它的作用是将 Builder 作用于给定的源代码上,完成 Lifecycle 的指令。
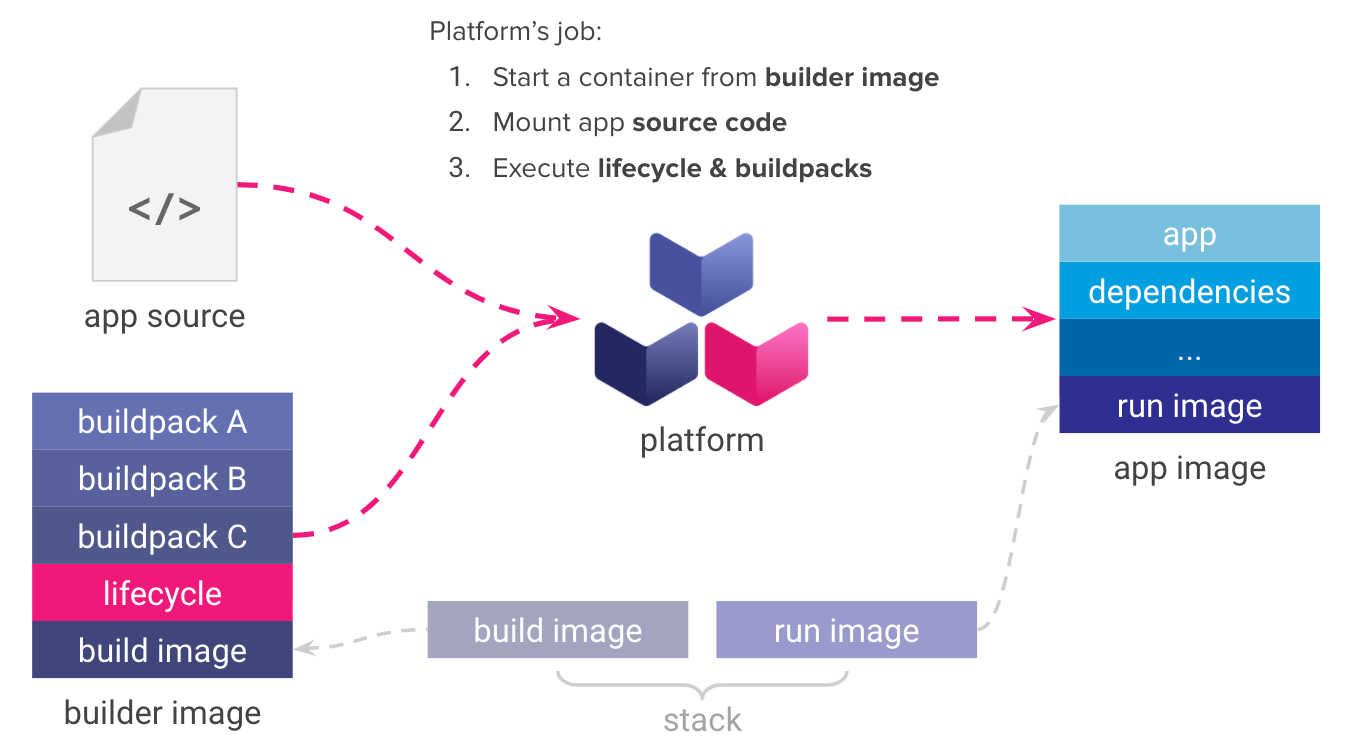
在这个过程中,Builder 会将源代码构建为 app,这个时候 app 是在 build image 中的。这个时候根据 Lifecycle 中的 rebase 接口,底层逻辑是是用 ABI(application binary interface) 将 app 工件从 build image 转换到 run image 上。这就是最后的 OCI 镜像。
常用的 Platform 有 Tekton 和 CNB 的 Pack。接下来我们将使用 Pack 来体验如何使用 Buildpacks 构建镜像。
安装 Pack CLI 工具
目前 Pack CLI 支持 Linux、MacOS 和 Windows 平台,以 Ubuntu 为例,安装命令如下:
$ sudo add-apt-repository ppa:cncf-buildpacks/pack-cli
$ sudo apt-get update
$ sudo apt-get install pack-cli
查看版本:
$ pack version
0.22.0+git-26d8c5c.build-2970
注意:在使用 Pack 之前,需要先安装并运行 Docker。
目前 Pack CLI 只支持 Docker,不支持其他容器运行时(比如 Containerd 等)。但 Podman 可以通过一些 hack 来变相支持,以 Ubuntu 为例,大概步骤如下:
先安装 podman。
$ . /etc/os-release
$ echo "deb https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/xUbuntu_${VERSION_ID}/ /" | sudo tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable.list
$ curl -L "https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/xUbuntu_${VERSION_ID}/Release.key" | sudo apt-key add -
$ sudo apt-get update
$ sudo apt-get -y upgrade
$ sudo apt-get -y install podman
然后启用 Podman Socket。
$ systemctl enable --user podman.socket
$ systemctl start --user podman.socket
指定 DOCKER_HOST 环境变量。
$ export DOCKER_HOST="unix://$(podman info -f "{{.Host.RemoteSocket.Path}}")"
最终就可以实现在 Podman 容器运行时中使用 Pack 来构建镜像。详细配置步骤可参考 Buildpacks 官方文档。
使用 Pack 构建 OCI 镜像
安装完 Pack 之后,我们可以通过 CNB 官方提供的 samples 加深对 Buildpacks 原理的理解。这是一个 Java 示例,构建过程中无需安装 JDK、运行 Maven 或其他构建环境,Buildpacks 会为我们处理好这些。
首先克隆示例仓库:
$ git clone https://github.com/buildpacks/samples.git
后面我们将使用 bionic 这个 Builder 来构建镜像,先来看下该 Builder 的配置:
$ cat samples/builders/bionic/builder.toml
# Buildpacks to include in builder
[[buildpacks]]
id = "samples/java-maven"
version = "0.0.1"
uri = "../../buildpacks/java-maven"
[[buildpacks]]
id = "samples/kotlin-gradle"
version = "0.0.1"
uri = "../../buildpacks/kotlin-gradle"
[[buildpacks]]
id = "samples/ruby-bundler"
version = "0.0.1"
uri = "../../buildpacks/ruby-bundler"
[[buildpacks]]
uri = "docker://cnbs/sample-package:hello-universe"
# Order used for detection
[[order]]
[[order.group]]
id = "samples/java-maven"
version = "0.0.1"
[[order]]
[[order.group]]
id = "samples/kotlin-gradle"
version = "0.0.1"
[[order]]
[[order.group]]
id = "samples/ruby-bundler"
version = "0.0.1"
[[order]]
[[order.group]]
id = "samples/hello-universe"
version = "0.0.1"
# Stack that will be used by the builder
[stack]
id = "io.buildpacks.samples.stacks.bionic"
run-image = "cnbs/sample-stack-run:bionic"
build-image = "cnbs/sample-stack-build:bionic"
builder.toml 文件中完成了对 Builder 的定义,配置结构可以划分为 3 个部分:
- [[buildpacks]] 语法标识用于定义 Builder 所包含的 Buildpacks。
- [[order]] 用于定义 Builder 所包含的 Buildpacks 的执行顺序。
- [[stack]] 用于定义 Builder 将运行在哪个基础环境之上。
我们可以使用这个 builder.toml 来构建自己的 builder 镜像:
$ cd samples/builders/bionic
$ pack builder create cnbs/sample-builder:bionic --config builder.toml
284055322776: Already exists
5b7c18d5e17c: Already exists
8a0af02bbad1: Already exists
0aa0fb9222a5: Download complete
3d56f4bc2c9a: Already exists
5b7c18d5e17c: Already exists
284055322776: Already exists
8a0af02bbad1: Already exists
a967314b5694: Already exists
a00d148009e5: Already exists
dbb2c49b44e3: Download complete
53a52c7f9926: Download complete
0cceee8a8cb0: Download complete
c238db6a02a5: Download complete
e925caa83f18: Download complete
Successfully created builder image cnbs/sample-builder:bionic
Tip: Run pack build <image-name> --builder cnbs/sample-builder:bionic to use this builder
接着,进入 samples/apps 目录,使用 pack 工具和 builder 镜像,完成应用的构建。当构建成功后,会产出一个名为 sample-app 的 OCI 镜像。
$ cd ../..
$ pack build --path apps/java-maven --builder cnbs/sample-builder:bionic sample-app
最后使用 Docker 运行这个 sample-app 镜像:
$ docker run -it -p 8080:8080 sample-app
访问 http://localhost:8080,如果一切正常,你可以在浏览器中看见如下的界面:

现在我们再来观察一下之前构建的镜像:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
cnbs/sample-package hello-universe e925caa83f18 42 years ago 4.65kB
sample-app latest 7867e21a60cd 42 years ago 300MB
cnbs/sample-builder bionic 83509780fa67 42 years ago 181MB
buildpacksio/lifecycle 0.13.1 76412e6be4e1 42 years ago 16.4MB
镜像的创建时间竟然都是固定的时间戳:42 years ago。这是为什么呢?如果时间戳不固定,每次构建镜像的 hash 值都是不同的,一旦 hash 值不一样,就不太容易判断镜像的内容是否相同了。使用固定的时间戳,就可以重复利用之前的构建过程中创建的 layers。
总结
Cloud Native Buildpacks 代表了现代软件开发的一个重大进步,在大部份场景下相对于 Dockerfile 的好处是立杆见影的。虽然大型企业需要投入精力重新调整 CI/CD 流程或编写自定义 Builder,但从长远来看可以节省大量的时间和维护成本。
本文介绍了 Cloud Native Buildpacks(CNB) 的起源以及相对于其他工具的优势,并详细阐述了 CNB 的工作原理,最后通过一个简单的示例来体验如何使用 CNB 构建镜像。后续的文章将会介绍如何创建自定义的 Builder、Buildpack、Stack,以及函数计算平台(例如,OpenFunction、Google Cloud Functions)如何利用 CNB 提供的 S2I 能力,实现从用户的函数代码到最终应用的转换过程。
基于 OpenFunction 构建 FaaS 化的数据归档系统
OpenFunction 是 KubeSphere 社区开源的一个函数即服务(FaaS: Function-as-a-Service)项目,作为一个 Serverless 应用框架,它能够帮助开发者专注于他们的业务逻辑,而不必担心底层运行环境和基础设施。利用 OpenFunction 优秀的云原生 FasS 平台能力,我们尝试构建了一个 Serverless 化的数据归档(及分发)系统,用于满足业务上可扩展、运维上资源可弹性伸缩、以及开发上高效简便的几个核心诉求。
本文将分为一下几个部分来展开:
- 首先是介绍我们的主要业务场景和系统构建的背景
- 其次是分析为何选择 Serverless 的架构方式来进行系统建设
- 最后我们将简要的介绍如何通过 OpenFunction 来实现系统并满足我们的核心研发诉求
业务场景介绍
数据归档 是各类在线业务系统中的一项常见功能需求,在自动驾驶领域也不例外。对于自动驾驶的云端平台而言,抛开通常会专门维护管理的用于 AI 训练的大数据,会有大量在常态化运营状态下生成的车端数据,这些数据是非常具有时效性特征的(即数据的价值随着时间的流逝而流失),对于这部分数据我们通常会分阶段地对他们进行存储的降级(即逐步向低成本大容量的低频存储搬迁)。
这样的存储降级及搬迁虽然看似不如运营业务逻辑复杂,但在实际实施过程中其实还是面临不少问题的,处理的不好甚至可能对生成运营环境产生影响。我们这里以几个典型的问题为例:
- 数据存储种类多:不管是数据源还是目标数据存储,通常在数据处理相关的业务场景下都会有比较多的种类。单从类型角度来看,关系型数据存储、键值数据存储、文档型存储、时序数据存储、对象存储就已经种类繁多了,更不用说每个分类下面还有非常多有代表性的数据库或数据存储产品,那如何高效的面向这些存储获取和写入数据就是首先要解决的问题。
- 数据规模不统一:存储种类繁多的另一个引申问题是不同业务对于存储的使用情况也存在差异。比如对于自动驾驶或者物联网场景,在运营过程中会产生大量时序性数据;对于 OA 办公自动化领域可能产生的文档型数据就会比较多;所以即使同样是进行数据归档,不同的数据存储在不同的业务系统中实际产生的工作负载也会有很大的差异。
- 同异步操作混合:在具体实施归档的过程中,也是由于数据存储的原生读写方式不同,往往存在同步和异步的数据访问方式混用的情况,这对数据操作服务的编写提出了挑战。
- 业务过程可观察:上述几个问题综合在一起,会需要我们为整个业务过程的执行提供更好的可观察性能力支持 —— 为每一次批量操作提供尽可能细粒度的执行过程状态反馈。
OpenFunction 可以带来什么
基于这几个典型问题,我们首先不难想到可以利用微服务架构作为解决 “数据存储种类繁多” 这个核心问题的基础支撑,这样我们可以把操作不同数据存储的操作封装到一个个微服务中,并分派给不同的团队成员使用自己偏好和熟悉的编程语言进行开发。
但这样的拆分对于任务串联带来了困难,同时也需要解决数据规模增长后是否能够对应扩展服务规模的问题。从服务按需扩展这个弹性伸缩的问题上,我们倒是可以进一步想到 Serverless 架构是一个不错的解决思路,虽然任务串联仍然是个问题,同时对于同步和异步的混合操作可能还是没有什么 Serverless 体系内的规范可以指导服务开发。
这些问题一直伴随着我们的技术选型过程,直到我们发现了 OpenFunction 项目。下面我们用一个表格来大致对比一下三种架构方案在解决这些问题上的思路。
| OpenFunction FaaS 方案 | 一般 Serverless 架构方案 | 基础微服务架构方案 | |
|---|---|---|---|
| 数据存储种类多 | 构建 “函数粒度” 的微服务来分别处理各类数据存储 | 构建 “应用或函数粒度” 微服务 | 构建 “应用粒度” 微服务 |
| 数据规模不统一 | 提供自动伸缩能力(基于 KEDA 提供,可缩至 0 副本) | 提供自动伸缩能力(可缩至 0 副本) | 可以实现自动伸缩(至少保留 1 个副本) |
| 同异步操作混合 | 同时具备同步及异步运行时框架(分别基于 Knative 和 Dapr 实现) | 比较少见有框架提供异步运行时框架 | 通常各服务各自实现(依靠服务框架) |
| 业务过程可观察 | 社区正在积极推进与 SkyWalking 等可观察性框架的对接 | 依靠 Serverless 框架自身能力 | 通常各服务各自实现(依靠服务框架) |
使用 OpenFunction 实现数据归档
在了解了基于 OpenFunction 来解决以上核心问题的思路后,我们便可以展开实际的业务系统构建工作。在 OpenFunction 的四套核心组件中(如以下 OpenFunction CRD 关系图 所示),我们主要会用到其中的 Function 和 Serving 这两大模块,Build 虽然也会使用但并不在业务执行阶段发挥作用,而 Events 模块暂时在现有系统中尚未引入(未来会用到)。

考虑到具体业务执行过程中存在较多长任务,因此下面所展示的系统业务架构中所有的 Function 都是通过基于 Dapr 实现的 OpenFuncAsync 异步方式来相互调用和串联的。
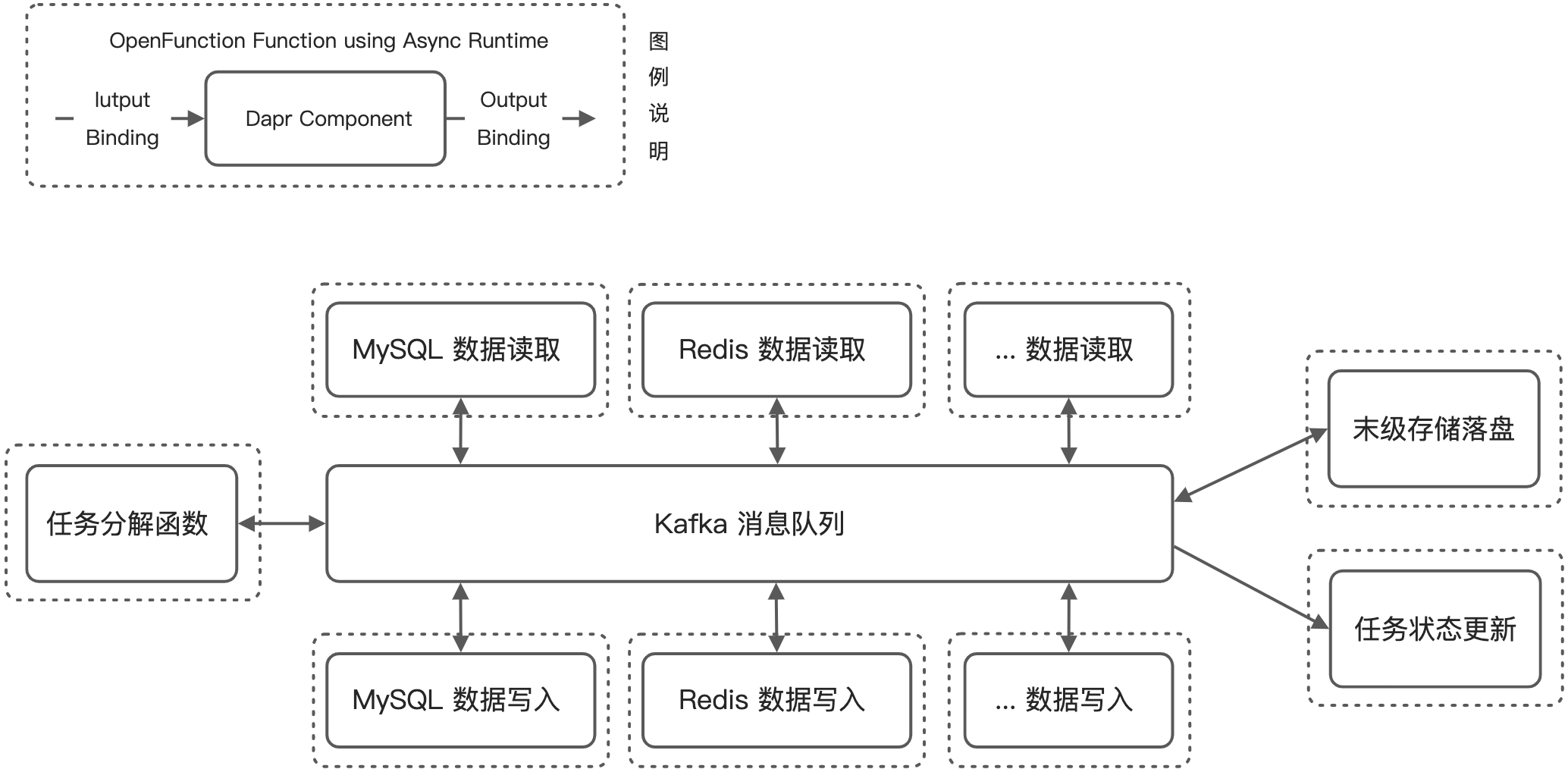
上图展示了我们基于 OpenFunction 构建的数据归档系统的核心业务架构,业务流程方面其实很直接 —— 由一个任务拆解函数作为总入口,各个存储读写函数负责操作各类数据存储,最后所有数据汇入末级存储并调用状态更新函数汇报任务执行结果。下面让我们重点看一下 OpenFunction 帮助我们做了哪些工作:
- 首先,我们编写的 Go、Node.js 的函数通过 OpenFunction Build 被封装成对应的函数服务镜像供加载
- 然后我们通过 Function CRD 让我们的函数在异步执行模式(Async Serving)下开始运行:
- 我们指定的函数服务会被进一步封装成 Dapr Component
- 我们可以按需声明一些关联的中间件服务(需要 Dapr Component Bindings 或 Pub/Sub Brokers 支持)
- 对应不同的中间件,函数可以和它们做 Input 和 Output 的绑定(支持 Bindings 和 Pub/Sub)
- 由于 Serverless 架构的特性,函数服务在无流量时是被伸缩到 0 副本的,OpenFunction 会利用 KEDA ScaledObject 来监控流量并实施弹性伸缩
OpenFunction 与 Dapr 惺惺相惜
不难发现 Dapr 是 OpenFunction 异步函数运行时的核心组件,从我们目前的开发使用体验来看,他们的作用是双向互补的。
- Dapr 使 OpenFunction 具备了良好的异步业务处理能力,而且在开发中我们也可以直接利用 Dapr 原生的体系做一些异步能力的扩展
- OpenFunction 给 Dapr 提供了一个很好的落地平台,而且一定程度上简化了 Dapr 的应用配置以及使用方式,比如 Component 和 Binding 配置的整合,比如调用 Dapr Binding 的方式也从调用 Dapr Sidecar 入口地址转为了简单的一行代码,
ctx.Send(data, "dapr_component_name")
未来工作展望
如本业务案例所示,OpenFunction 不但以 Serverless 的方式提升了数据处理和流转业务的灵活度,还可以通过 OpenFunction 较为独有的异步函数运行时框架串联函数和中间件,让更多的开发时间可以专注在业务开发中。特别是对于 Dapr 框架熟悉的小伙伴完全可以利用 OpenFunction 来驱动和加速 Dapr 应用的开发和落地。
在本业务系统的持续迭代过程中,我们也会逐步引入同步函数运行时的使用,比如目前入口的任务拆解函数也是异步触发的,这个其实对于接入前端应该不是很方便,未来我们计划引入 0.5.0 里程碑中会发布的 Domain(即同步函数绑定 Ingress 入口)能力,这样可以在入口函数层面都提供同步访问接口,也不影响之后的业务流程通过异步的消息通道进行组合串联。
快速上手云原生FaaS平台-OpenFunction
经过超过三年的开发,Knative近期发布了1.0版本,标致着它的核心组件(Serving,Eventing)已经可用。这说明了整个Kubernetes社区内包括 OpenFaas,OpenWhisk,Kubeless,Fn等等在内的无服务器框架生态的成熟度。这些框架仅仅专注提供函数的容器化打包,但并不提供完整功能的函数即服务(FaaS)平台。
OpenFunction是(KubeSphere)[https://kubesphere.io/]团队支持的一个开源项目,2021年三月发布了第一个版本。它旨在增强现有的框架,在Kubernetes上构建并运行事件驱动的函数,提供一个端到端的FaaS平台。
OpenFunction组件
目前,OpenFunction分为四个自定义的资源类型(CRDs):
Function: 通过协调Builder和Serving组件来控制整个函数的生命周期Builder: 将函数编译、构建、发布到镜像仓库Serving: 运行函数并控制扩缩容事件Domain: 为函数提供一个服务入口
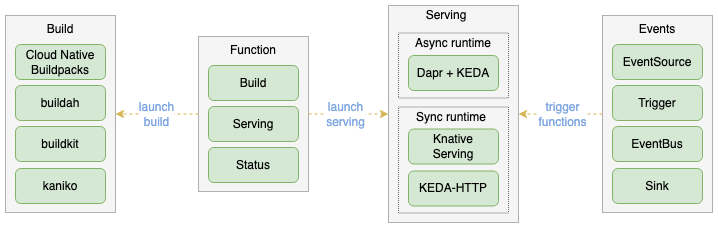
OpenFunction在引擎内使用以下几个开源项目来实现每个CRD:
Builder使用了 (Shipwright)[https://shipwright.io/] 和 (Cloud Navite Build Packs)[https://buildpacks.io/] 来编译和构建函数代码到容器内Serving支持 (Knative)[https://knative.dev/docs/]和OpenFuncAsyns,运行时基于(KEDA)[https://keda.sh/]和(Dapr)[https://dapr.io/]Domain默认使用nginx-ingress- 另外,(cert manager)[https://cert-manager.io/] 和 (Tekton Pipeline)[https://tekton.dev/] 用来将所有的组件组合起来
OpenFunction 提供了一个便捷的命令行工具用来安装所有的组件,但在这个演示中,我们会使用原始的安装脚本在Minikube中安装和运行一些示例。
启动Minikube
OpenFunction 被设计可以运行在任何Kubernetes发行版内,在这个演示中,我们使用Minikube作为Kubernetes演示环境。由于OpenFunction的组件依赖,Minikube至少需要2个CPU和4GB的内存:
$ minikube start -cpus 2 -memory 4096
备注: minikube需要运行1.19或更高版本的Kubernetes
接下来,我们需要为Builder组件提供一个用来推送镜像的凭据。这里我会使用Docker,理论上任何镜像仓库都可以使用。
$ kubectl create secret docker-registry regcred -docker -server=https://index.docker.io/v1/ -docker-username=<myUsername> -docker-password=<myPassword>
安装OpenFunction
现在我们做好了安装OpenFunction的准备工作。克隆(OpenFunction)[https://github.com/OpenFunction/OpenFunction]的代码仓库并检查hack/deploy.sh脚本。
作为一个基础的演示,我们只需要Shipwright,Knative,cert-manager作为依赖。
$ sh hack/deploy.sh -with-shipwright -with-knative -with-cert-manager
下一步,安装OpenFunction:
$ kubectl create -f https://github.com/OpenFunction/OpenFunction/releases/download/v0.4.0/bundle.yaml
等待controller manager的状态变为Running且健康状态为正常.
$ kubectl get po -n openfunction -w
NAME READY STATUS RESTARTS AGE
openfunction-controller-manager-6955498c9b-hjql7 2/2 Running 0 2m2s
部署第一个函数
示例中所有的应用都在samples仓库中提供,但是当前只有golang版本有完整的文档。我也使用golang作为示例,如果使用其他支持的语言,只需要修改以下yaml文件的必要字段。(openfunction.yaml):
apiVersion: core.openfunction.io/v1alpha2
kind: Function
metadata:
name: function-sample
spec:
version: "v1.0.0"
image: "<your-docker-registry>/sample-go-func:latest"
imageCredentials:
name: regcred
port: 8080 # default to 8080
build:
builder: openfunction/builder:v1
env:
FUNC_NAME: "HelloWorld"
FUNC_TYPE: "http"
srcRepo:
url: "https://github.com/OpenFunction/samples.git"
sourceSubPath: "latest/functions/Knative/hello-world-go"
serving:
runtime: "Knative" # default to Knative
template:
containers:
- name: function
imagePullPolicy: Always
创建函数:
$ kubectl create -f openfunction.yaml
如果发生错误,检查创建出来的Pod或者检查Pod的日志。
$ kubectl get functions.core.openfunction.io
$ kubectl get servings.core.openfunction.io
测试示例函数
当函数工作负载成为运行状态并且健康状态是正常时,我们可以将服务进行暴露来触发事件。
新建一个终端,创建一个可以访问minikube内部服务的tunnel
$ minikube tunnel
使用如下命令获取我们的函数URL:
$ kubectl get svc
访问服务(替换为你环境中的URL):
$ curl http://serving-rjgqg-ksvc-zf8j2.default.127.0.0.1.sslip.io
正常情况下我们会看到 “Hello,World!”
未来的工作
由于OpenFunction 使用 Knative 实现自身的运行时组件,所以可以兼容所有的Knative examples 。从个人经验来看,对于已经使用Kubernetes集群的团队,无服务器框架可以让开发人员快速运行任意的业务函数(例如:当事件X发生时发送邮件、当webhoo被k触发时执行一个数据转换任务)。在本文的第二部分中,我们将探索一个更现实的无服务器场景。
从 0 到 1,打造新一代开源函数计算平台
无服务器计算,即通常所说的 Serverless,已经成为当前云原生领域炙手可热的名词,是继 IaaS,PaaS 之后云计算发展的下一波浪潮。Serverless 强调的是一种架构思想和服务模型,让开发者无需关心基础设施(服务器等),而是专注到应用程序业务逻辑上。加州大学伯克利分校在论文 《A Berkeley View on Serverless Computing》 中给出了两个关于 Serverless 的核心观点:
- 有服务的计算并不会消失,但随着 Serverless 的成熟,有服务计算的重要性会逐渐降低。
- Serverless 最终会成为云时代的计算范式,它能够在很大程度上替代有服务的计算模式,并给 Client-Server 时代划上句号。
那么什么是 Serverless 呢?
Serverless 介绍
关于什么是 Serverless,加州大学伯克利分校在之前提到的论文中也给出了明确定义:Serverless computing = FaaS + BaaS。云服务按抽象程度从底层到上层传统的分类是硬件、云平台基本组件、PaaS、应用,但 PaaS 层的理想状态是具备 Serverless 的能力,因此这里我们将 PaaS 层替换成了 Serverless,即下图中的黄色部分。
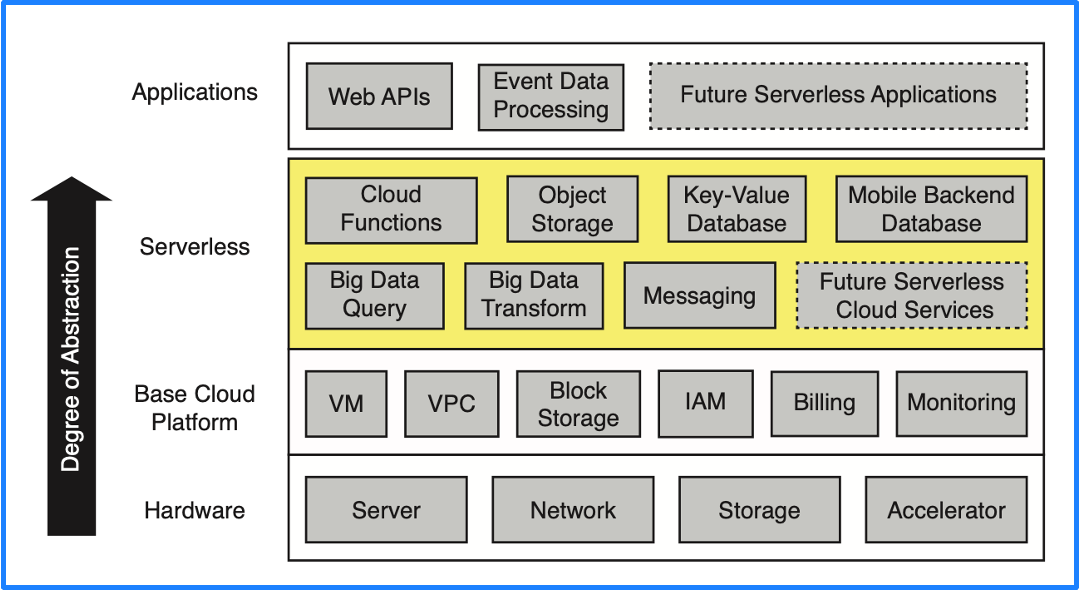
Serverless 包含两个组成部分 BaaS 和 FaaS,其中对象存储、关系型数据库以及 MQ 等云上基础支撑服务属于 BaaS(后端即服务),这些都是每个云都必备的基础服务,FaaS(函数即服务)才是 Serverless 的核心。
现有开源 Serverless 平台分析
KubeSphere 社区从 2020 年下半年开始对 Serverless 领域进行深度调研。经过一段时间的调研后,我们发现:
- 现有开源 FaaS 项目绝大多数启动较早,大部分都在 Knative 出现前就已经存在了;
- Knative 是一个非常杰出的 Serverless 平台,但是 Knative Serving 仅仅能运行应用,不能运行函数,还不能称之为 FaaS 平台;
- Knative Eventing 也是非常优秀的事件管理框架,但是设计有些过于复杂,用户用起来有一定门槛;
- OpenFaaS 是比较流行的 FaaS 项目,但是技术栈有点老旧,依赖于 Prometheus 和 Alertmanager 进行 Autoscaling,在云原生领域并非最专业和敏捷的做法;
- 近年来云原生 Serverless 相关领域陆续涌现出了很多优秀的开源项目如 KEDA、 Dapr、 Cloud Native Buildpacks(CNB)、 Tekton、 Shipwright 等,为创建新一代开源 FaaS 平台打下了基础。
综上所述,我们调研的结论就是:现有开源 Serverless 或 FaaS 平台并不能满足构建现代云原生 FaaS 平台的要求,而云原生 Serverless 领域的最新进展却为构建新一代 FaaS 平台提供了可能。
新一代 FaaS 平台框架设计
如果我们要重新设计一个更加现代的 FaaS 平台,它的架构应该是什么样子呢?理想中的 FaaS 框架应该按照函数生命周期分成几个重要的部分:函数框架 (Functions framework)、函数构建 (Build)、函数服务 (Serving) 和事件驱动框架 (Events Framework)。
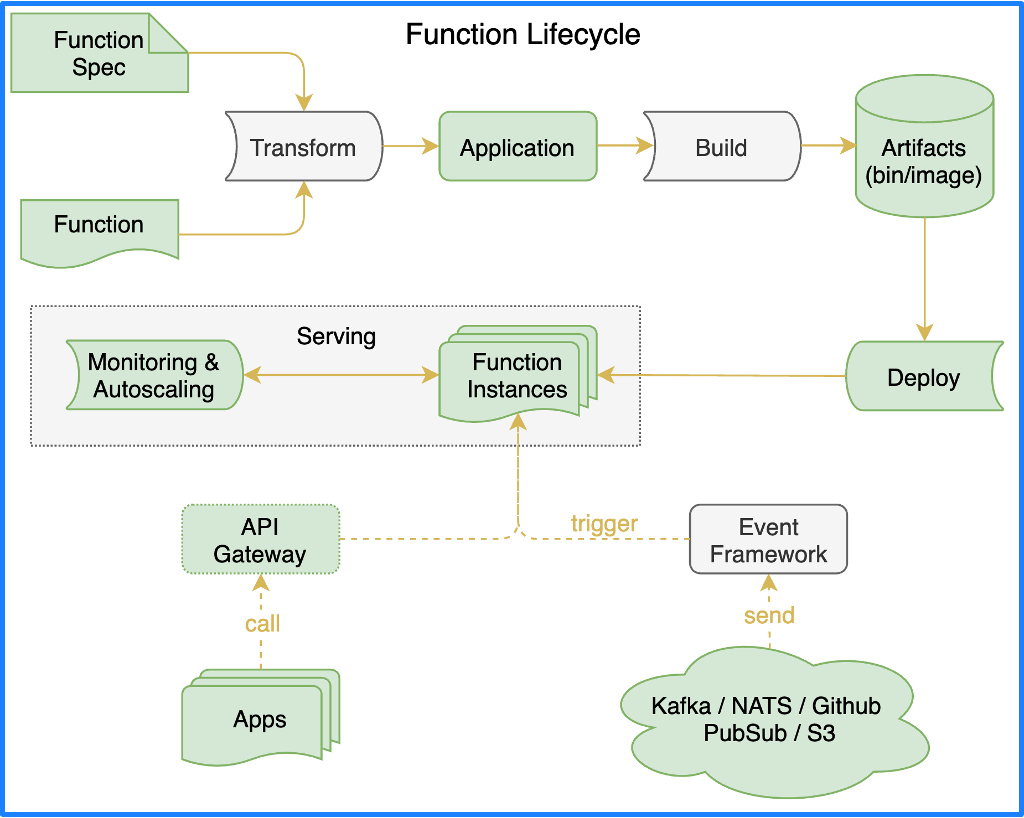
作为 FaaS,首先得有一个 Function Spec 来定义函数该怎么写,有了函数之后,还要转换成应用,这个转换的过程就是靠函数框架来完成;如果应用想在云原生环境中运行,就得构建容器镜像,构建流程依赖函数构建来完成;构建完镜像后,应用就可以部署到函数服务的运行时中;部署到运行时之后,这个函数就可以被外界访问了。
下面我们将重点阐述函数框架、函数构建和函数服务这几个部分的架构设计。
函数框架 (Functions framework)
为了降低开发过程中学习函数规范的成本,我们需要增加一种机制来实现从函数代码到可运行的应用之间的转换。这个机制需要制作一个通用的 main 函数来实现,这个函数用于处理通过 serving url 函数进来的请求。主函数中具体包含了很多步骤,其中一个步骤用于关联用户提交的代码,其余的用于做一些普通的工作(如处理上下文、处理事件源、处理异常、处理端口等等)。
在函数构建的过程中,构建器会使用主函数模板渲染用户代码,在此基础上生成应用容器镜像中的 main 函数。我们直接来看个例子,假设有这样一个函数。
package hello
import (
"fmt"
"net/http"
)
func HelloWorld(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Hello, World!\n")
}
经函数框架转换后会生成如下的应用代码:
package main
import (
"context"
"errors"
"fmt"
"github.com/OpenFunction/functions-framework-go/functionframeworks"
ofctx "github.com/OpenFunction/functions-framework-go/openfunction-context"
cloudevents "github.com/cloudevents/sdk-go/v2"
"log"
"main.go/userfunction"
"net/http"
)
func register(fn interface{}) error {
ctx := context.Background()
if fnHTTP, ok := fn.(func(http.ResponseWriter, *http.Request)); ok {
if err := functionframeworks.RegisterHTTPFunction(ctx, fnHTTP); err != nil {
return fmt.Errorf("Function failed to register: %v\n", err)
}
} else if fnCloudEvent, ok := fn.(func(context.Context, cloudevents.Event) error); ok {
if err := functionframeworks.RegisterCloudEventFunction(ctx, fnCloudEvent); err != nil {
return fmt.Errorf("Function failed to register: %v\n", err)
}
} else if fnOpenFunction, ok := fn.(func(*ofctx.OpenFunctionContext, []byte) ofctx.RetValue); ok {
if err := functionframeworks.RegisterOpenFunction(ctx, fnOpenFunction); err != nil {
return fmt.Errorf("Function failed to register: %v\n", err)
}
} else {
err := errors.New("unrecognized function")
return fmt.Errorf("Function failed to register: %v\n", err)
}
return nil
}
func main() {
if err := register(userfunction.HelloWorld); err != nil {
log.Fatalf("Failed to register: %v\n", err)
}
if err := functionframeworks.Start(); err != nil {
log.Fatalf("Failed to start: %v\n", err)
}
}
其中高亮的部分就是前面用户自己写的函数。在启动应用之前,先对该函数进行注册,可以注册 HTTP 类的函数,也可以注册 cloudevents 和 OpenFunction 函数。注册完成后,就会调用 functionframeworks.Start 启动应用。
函数构建 (Build)
有了应用之后,我们还要把应用构建成容器镜像。目前 Kubernetes 已经废弃了 dockershim,不再把 Docker 作为默认的容器运行时,这样就无法在 Kubernetes 集群中以 Docker in Docker 的方式构建容器镜像。还有没有其他方式来构建镜像?如何管理构建流水线?
Tekton 是一个优秀的流水线工具,原来是 Knative 的一个子项目,后来捐给了 CD 基金会 (Continuous Delivery Foundation)。Tekton 的流水线逻辑其实很简单,可以分为三个步骤:获取代码,构建镜像,推送镜像。每一个步骤在 Tekton 中都是一个 Task,所有的 Task 串联成一个流水线。
作容器镜像有多种选择,比如 Kaniko、Buildah、BuildKit 以及 Cloud Native Buildpacks(CNB)。其中前三者均依赖 Dockerfile 去制作容器镜像,而 Cloud Native Buildpacks(CNB)是云原生领域最新涌现出来的新技术,它是由 Pivotal 和 Heroku 发起的,不依赖于 Dockerfile,而是能自动检测要 build 的代码,并生成符合 OCI 标准的容器镜像。这是一个非常惊艳的技术,目前已经被 Google Cloud、IBM Cloud、Heroku、Pivotal 等公司采用,比如 Google Cloud 上面的很多镜像都是通过 Cloud Native Buildpacks(CNB)构建出来的。
面对这么多可供选择的镜像构建工具,如何在函数构建的过程中让用户自由选择和切换镜像构建的工具?这就需要用到另外一个项目 Shipwright,这是由 Red Hat 和 IBM 开源的项目,专门用来在 Kubernetes 集群中构建容器镜像,目前也捐给了 CD 基金会。使用 Shipwright,你就可以在上述四种镜像构建工具之间进行灵活切换,因为它提供了一个统一的 API 接口,将不同的构建方法都封装在这个 API 接口中。
我们可以通过一个示例来理解 Shipwright 的工作原理。首先需要一个自定义资源 Build 的配置清单:
apiVersion: shipwright.io/v1alpha1
kind: Build
metadata:
name: buildpack-nodejs-build
spec:
source:
url: https://github.com/shipwright-io/sample-nodejs
contextDir: source-build
strategy:
name: buildpacks-v3
kind: ClusterBuildStrategy
output:
image: docker.io/${REGISTRY_ORG}/sample-nodejs:latest
credentials:
name: push-secret
这个配置清单分为 3 个部分:
- source 表示去哪获取源代码;
- output 表示源代码构建的镜像要推送到哪个镜像仓库;
- strategy 指定了构建镜像的工具。
其中 strategy 是由自定义资源 ClusterBuildStrategy 来配置的,比如使用 buildpacks 来构建镜像,ClusterBuildStrategy 的内容如下:

这里分为两个步骤,一个是准备环境,一个是构建并推送镜像。每一步都是 Tekton 的一个 Task,由 Tekton 流水线来管理。
可以看到,Shipwright 的意义在于将镜像构建的能力进行了抽象,用户可以使用统一的 API 来构建镜像,通过编写不同的 strategy 就可以切换不同的镜像构建工具。
函数服务 (Serving)
函数服务 (Serving) 指的是如何运行函数/应用,以及赋予函数/应用基于事件驱动或流量驱动的自动伸缩的能力 (Autoscaling)。CNCF Serverless 白皮书定义了函数服务的四种调用类型:
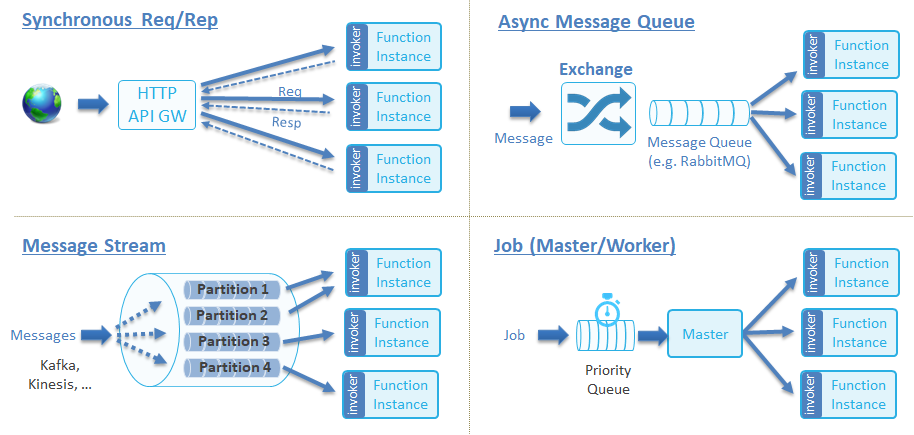
我们可以对其进行精简一下,主要分为两种类型:
- 同步函数:客户端必须发起一个 HTTP 请求,然后必须等到函数执行完成并获取函数运行结果后才返回。
- 异步函数:发起请求之后直接返回,无需等待函数运行结束,具体的结果通过 Callback 或者 MQ 通知等事件来通知调用者,即事件驱动 (Event Driven)。
同步函数和异步函数分别都有不同的运行时来实现:
- 同步函数方面,Knative Serving 是一个非常优秀的同步函数运行时,具备了强大的自动伸缩能力。除了 Knative Serving 之外,还可以选择基于 KEDA http-add-on 配合 Kubernetes 原生的 Deployment 来实现同步函数运行时。这种组合方法可以摆脱对 Knative Serving 依赖。
- 异步函数方面,可以结合 KEDA 和 Dapr 来实现。KEDA 可以根据事件源的监控指标来自动伸缩 Deployment 的副本数量;Dapr 提供了函数访问 MQ 等中间件的能力。
Knative 和 KEDA 在自动伸缩方面的能力不尽相同,下面我们将展开分析。
Knative 自动伸缩
Knative Serving 有 3 个主要组件:Autoscaler、Serverless 和 Activator。Autoscaler 会获取工作负载的 Metric(比如并发量),如果现在的并发量是 0,就会将 Deployment 的副本数收缩为 0。但副本数缩为 0 之后函数就无法调用了,所以 Knative 在副本数缩为 0 之前会把函数的调用入口指向 Activator。
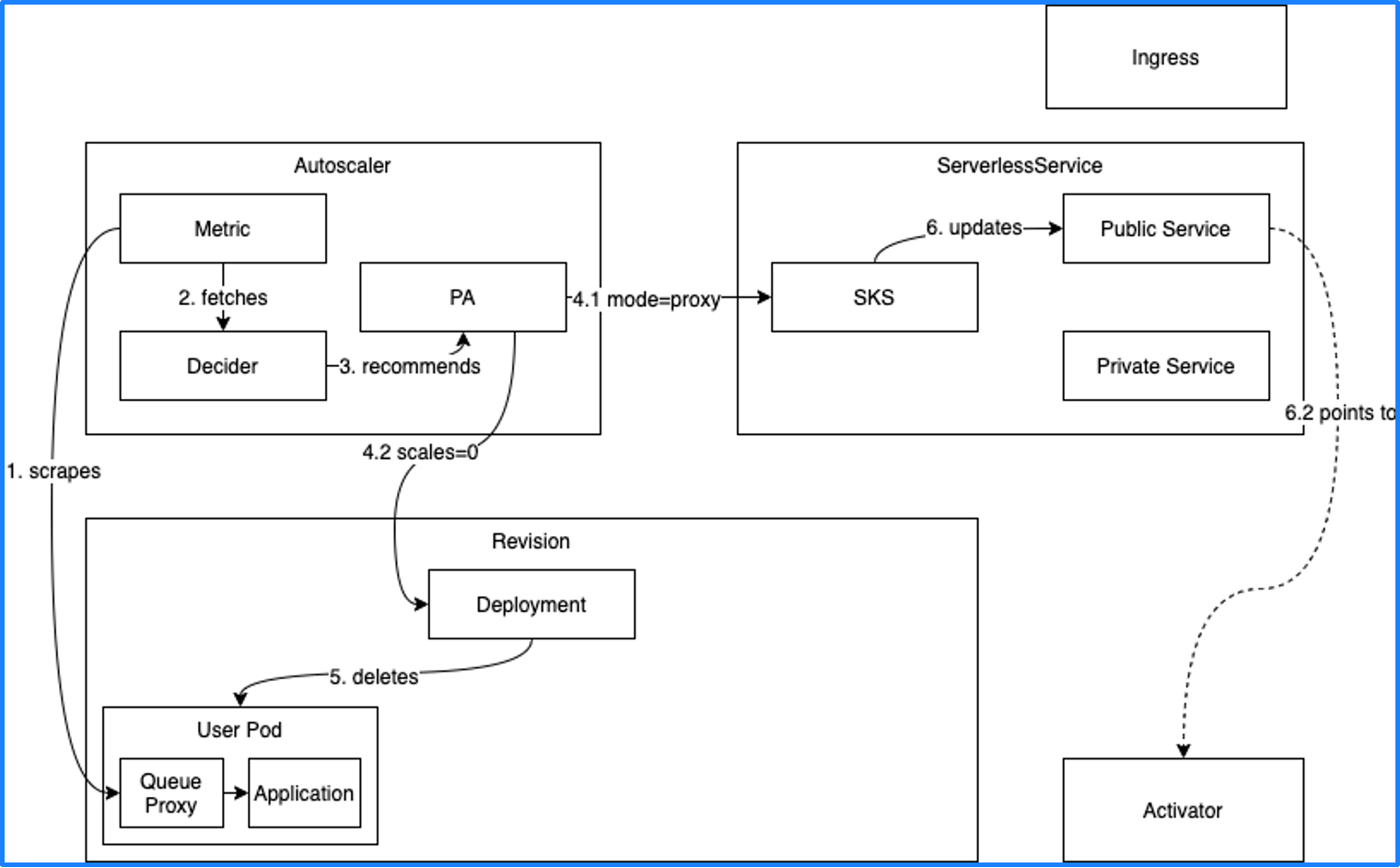
当有新的流量进入时,会先进入 Activator,Activator 接收到流量后会通知 Autoscaler,然后 Autoscaler 将 Deployment 的副本数扩展到 1,最后 Activator 会将流量转发到实际的 Pod 中,从而实现服务调用。这个过程也叫冷启动。

由此可知,Knative 只能依赖 Restful HTTP 的流量指标进行自动伸缩,但现实场景中还有很多其他指标可以作为自动伸缩的依据,比如 Kafka 消费的消息积压,如果消息积压数量过多,就需要更多的副本来处理消息。要想根据更多类型的指标来自动伸缩,我们可以通过 KEDA 来实现。
KEDA 自动伸缩
KEDA 需要和 Kubernetes 的 HPA 相互配合来达到更高级的自动伸缩的能力,HPA 只能实现从 1 到 N 之间的自动伸缩,而 KEDA 可以实现从 0 到 1 之间的自动伸缩,将 KEDA 和 HPA 结合就可以实现从 0 到 N 的自动伸缩。
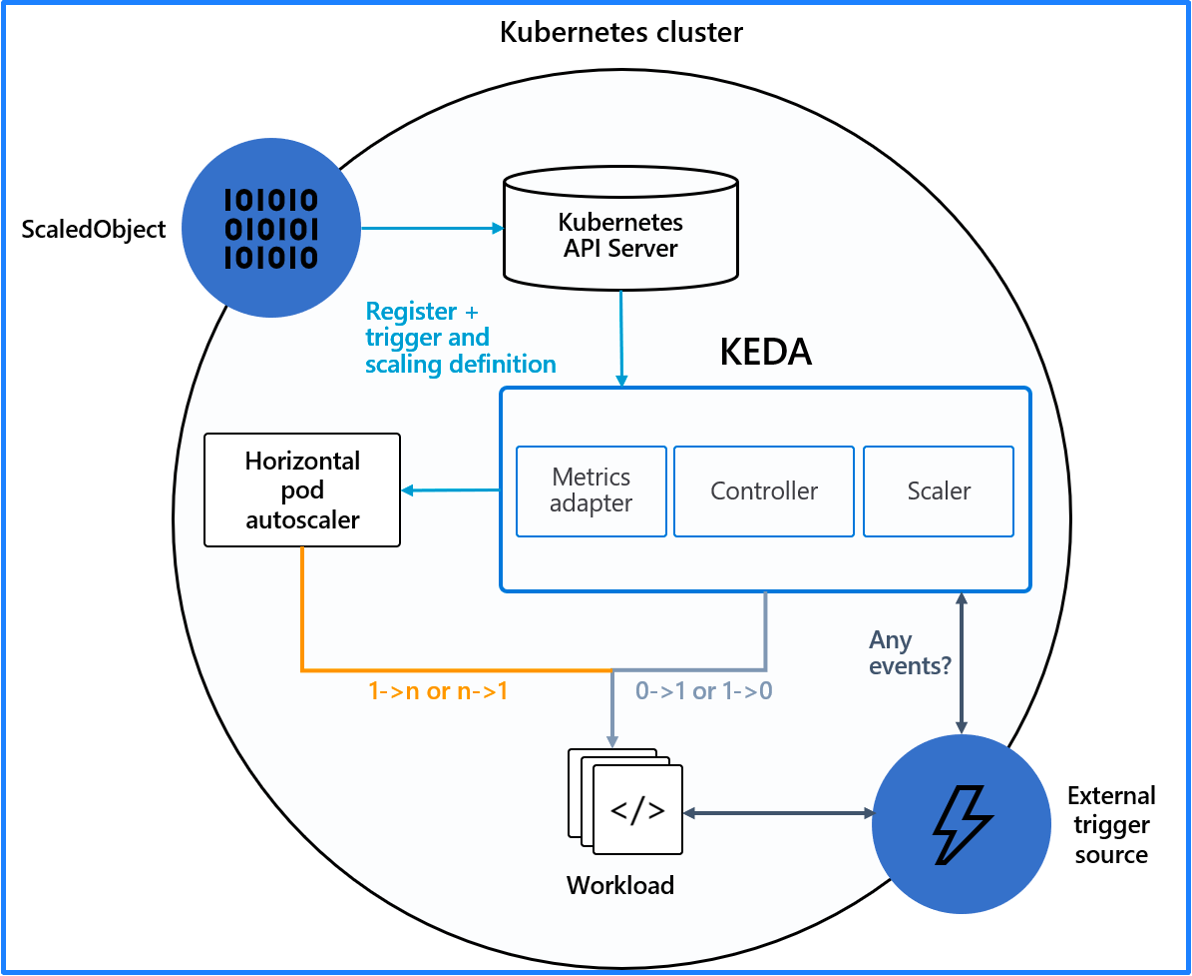
KEDA 可以根据很多类型的指标来进行自动伸缩,这些指标可以分为这么几类:
- 云服务的基础指标,比如 AWS 和 Azure 的相关指标;
- Linux 系统相关指标,比如 CPU、内存;
- 开源组件特定协议的指标,比如 Kafka、MySQL、Redis、Prometheus。

例如要根据 Kafka 的指标进行自动伸缩,就需要这样一个配置清单:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: kafka-scaledobject
namespace: default
labels:
deploymentName: kafka-consumer-deployment # Required Name of the deployment we want to scale.
spec:
scaleTargetRef:
deploymentName: kafka-consumer-deployment # Required Name of the deployment we want to scale.
pollingInterval: 15
minReplicaCount: 0
maxReplicaCount: 10
cooldownPeriod: 30
triggers:
- type: kafka
metadata:
topic: logs
bootstrapServers: kafka-logs-receiver-kafka-brokers.default.svc.cluster.local
consumerGroup: log-handler
lagThreshold: "10"
副本伸缩的范围在 0~10 之间,每 15 秒检查一次 Metrics,进行一次扩容之后需要等待 30 秒再决定是否进行伸缩。
同时还定义了一个触发器,即 Kafka 服务器的 “logs” topic。消息堆积阈值为 10,即当消息数量超过 10 时,logs-handler 的实例数量就会增加。如果没有消息堆积,就会将实例数量减为 0。
这种基于组件特有协议的指标进行自动伸缩的方式比基于 HTTP 的流量指标进行伸缩的方式更加合理,也更加灵活。
虽然 KEDA 不支持基于 HTTP 流量指标进行自动伸缩,但可以借助 KEDA 的 http-add-on 来实现,该插件目前还是 Beta 状态,我们会持续关注该项目,等到它足够成熟之后就可以作为同步函数的运行时来替代 Knative Serving。
Dapr
现在的应用基本上都是分布式的,每个应用的能力都不尽相同,为了将不同应用的通用能力给抽象出来,微软开发了一个分布式应用运行时,即 Dapr (Distributed Application Runtime)。Dapr 将应用的通用能力抽象成了组件,不同的组件负责不同的功能,例如服务之间的调用、状态管理、针对输入输出的资源绑定、可观测性等等。这些分布式组件都使用同一种 API 暴露给各个编程语言进行调用。
函数计算也是分布式应用的一种,会用到各种各样的编程语言,以 Kafka 为例,如果函数想要和 Kafka 通信,Go 语言就得使用 Go SDK,Java 语言得用 Java SDK,等等。你用几种语言去访问 Kafka,就得写几种不同的实现,非常麻烦。
再假设除了 Kafka 之外还要访问很多不同的 MQ 组件,那就会更麻烦,用 5 种语言对接 10 个 MQ(Message Queue) 就需要 50 种实现。使用了 Dapr 之后,10 个 MQ 会被抽象成一种方式,即 HTTP/GRPC 对接,这样就只需 5 种实现,大大减轻了开发分布式应用的工作量。
由此可见,Dapr 非常适合应用于函数计算平台。
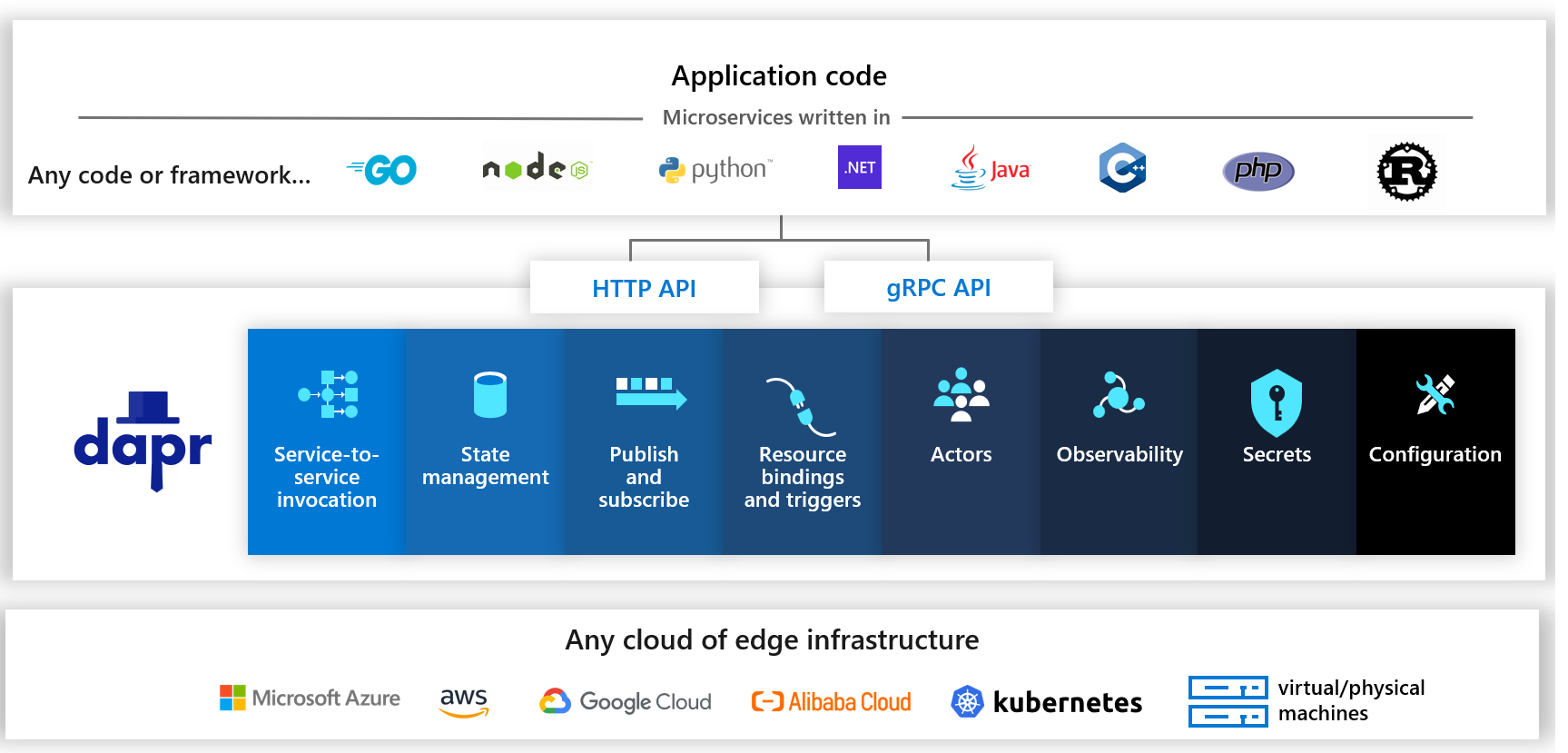
新一代开源函数计算平台 OpenFunction
结合上面讨论的所有技术,就诞生了 OpenFunction 这样一个开源项目,它的架构如图所示。
主要包含 4 个组件:
Function : 将函数转换为应用;
Build : 通过 Shipwright 选择不同的镜像构建工具,最终将应用构建为容器镜像;
Serving : 通过 Serving CRD 将应用部署到不同的运行时中,可以选择同步运行时或异步运行时。同步运行时可以通过 Knative Serving 或者 KEDA-HTTP 来支持,异步运行时通过 Dapr+KEDA 来支持。
Events : 对于事件驱动型函数来说,需要提供事件管理的能力。由于 Knative 事件管理过于复杂,所以我们研发了一个新型事件管理驱动叫 OpenFunction Events。
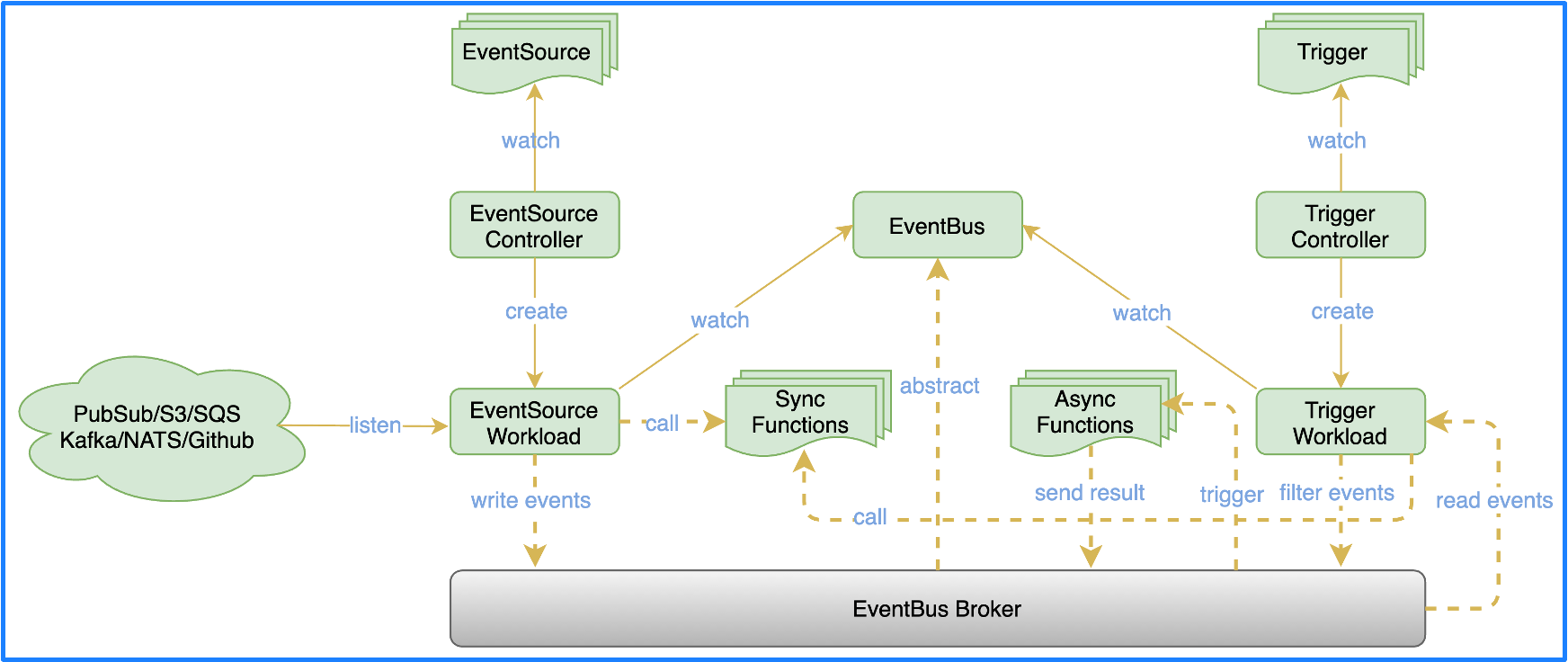
OpenFunction Events 借鉴了 Argo Events 的部分设计,并引入了 Dapr。整体架构分为 3 个部分:
- EventSource : 用于对接多种多样的事件源,通过异步函数来实现,可以根据事件源的指标自动伸缩,使事件的消费更加具有弹性。
- EventBus :
EventBus利用 Dapr 的能力解耦了 EventBus 与底层具体 Message Broker 的绑定,你可以对接各种各样的 MQ。EventSource消费事件之后有两种处理方式,一种是直接调用同步函数,然后等待同步函数返回结果;另一种方式是将其写入EventBus,EventBus 接收到事件后会直接触发一个异步函数。 - Trigger : Trigger 会通过各种表达式对
EventBus里面的各种事件进行筛选,筛选完成后会写入EventBus,触发另外一个异步函数。
关于 OpenFunction 的实际使用案例可以参考这篇文章:以 Serverless 的方式用 OpenFunction 异步函数实现日志告警。
OpenFunction Roadmap

OpenFunction 的第一个版本于今年 5 月份发布,从 v0.2.0 开始支持异步函数,v0.3.1 开始新增了 OpenFunction Events,并支持了 Shipwright,v0.4.0 新增了 CLI。
后续我们还会引入可视化界面,支持更多的 EventSource,支持对边缘负载的处理能力,通过 WebAssembly 作为更加轻量的运行时,结合 Rust 函数来加速冷启动速度。
加入 OpenFunction 社区
期待感兴趣的开发者加入 OpenFunction 社区。可以提出任何你对 OpenFunction 的疑问、设计提案与合作提议。
您可以在这里找到 OpenFunction 的一些典型使用案例: